Chapter 13 Download Modules
Although the full datasets of UCSC Xena can be downloaded in the repository page, it will spend unnecessary time and storage costs if we only want to obtain several molecular data for local analysis.
Therefore, two download modules are designed for the precise acquisition of raw data from TCGA/PCAWG/CCLE analysis (module 1) and UCSC Xena repository datasets (module 2).
- If you want to quickly query and obtain omics values of TPC samples, the module 1 is more suitable. In addition, non-omics annotation data of TPC is also available (e.g. tumor immune infiltration estimation).
- If you want to search one specific UCSC Xena dataset, especially for other hubs (e.g. TCGA GDC), the module 2 is more suitable.
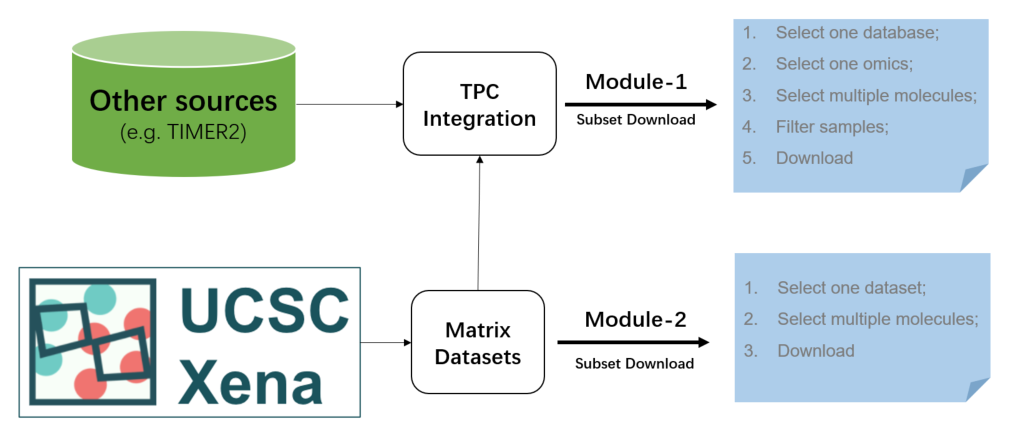
Figure 13.1: Two custom download modules
13.1 Download TPC datasets
There are two parts for omics (Left) and non-omics (Right) data, respectively.
13.1.1 Omics molecular data
Go to Chapter 1 if you have little knowledge about the UCSC Xena datasets.
- Select one database and set the candidate datasets (referring to Chapter 10);
- Select further samples through the quick or exact filters (referring to Chapter 11.2.1);
- Select one specific molecular type and its multiple identifiers in three ways (referring to Chapter 11.3.2);
- Click the “Query” button to fetch the eligible data and display in the right panel;
- Download the queried data into local CSV or RDA file.
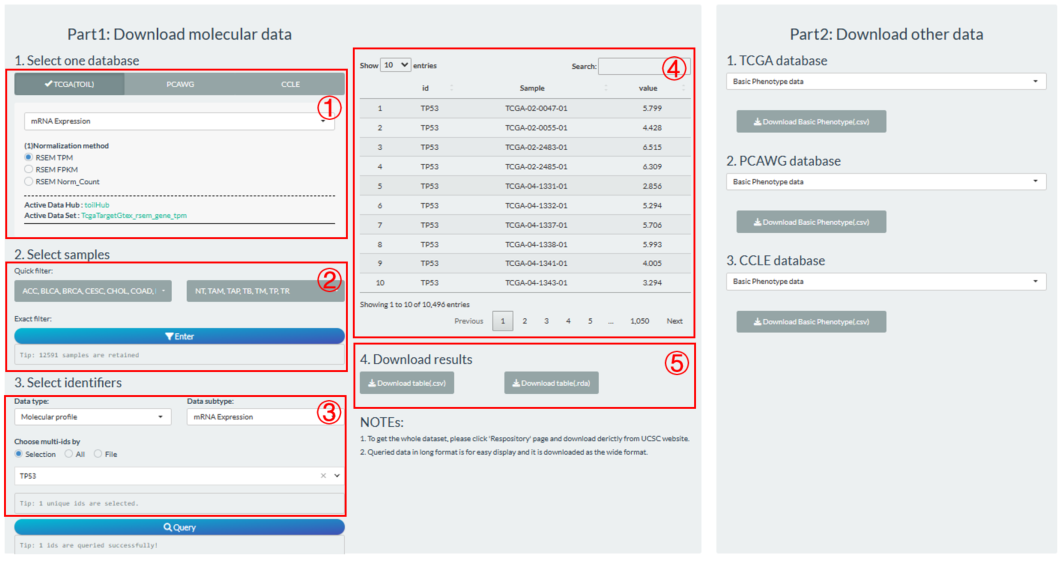
Figure 13.2: The steps of TPC omics molecular data fetch
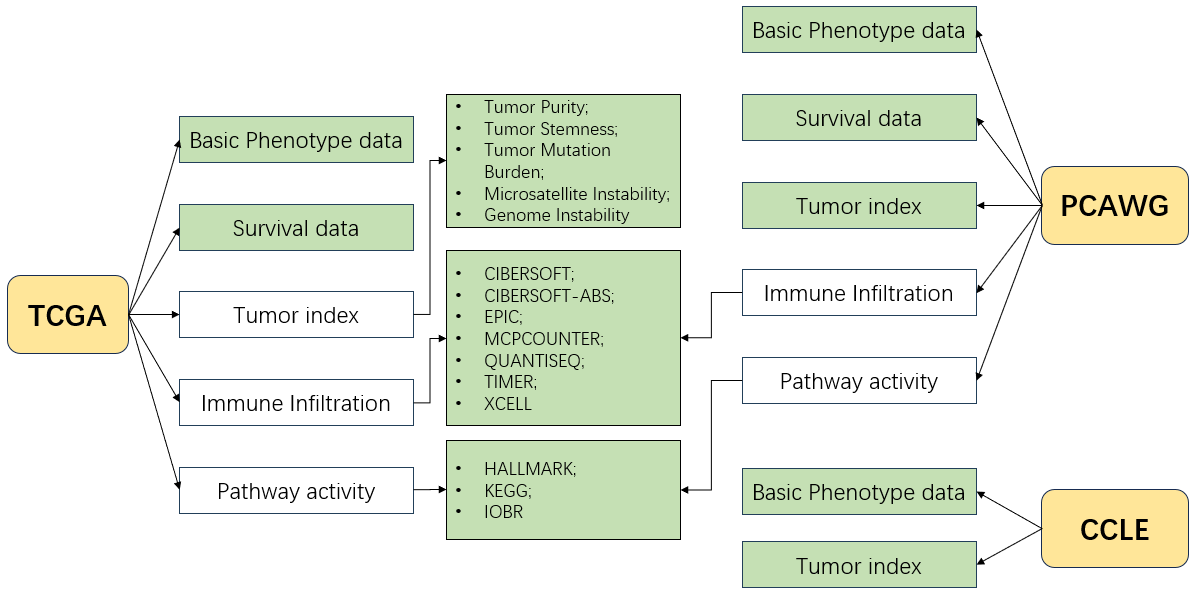
13.2 Download UCSC Xena datasets
Go to Chapter 1 if you have little knowledge about the UCSC Xena datasets.
- Select one data hub in UCSC Xena;
- Select one of candidate datasets by limiting the data format type and profile type;
- Load all available identifiers of the selected dataset. The Primary ID indicates the row names of dataset and the ProbeMap ID is more usable. For instance, among most mRNA dataset, their Primary IDs are usually Ensembl names and ProbeMap IDs are Symbol names;
- Select multiple identifiers or directly upload an id file;
- Click the “Query” button to fetch the eligible data and display in the right panel;
- Download the queried data into local CSV or RDA file.
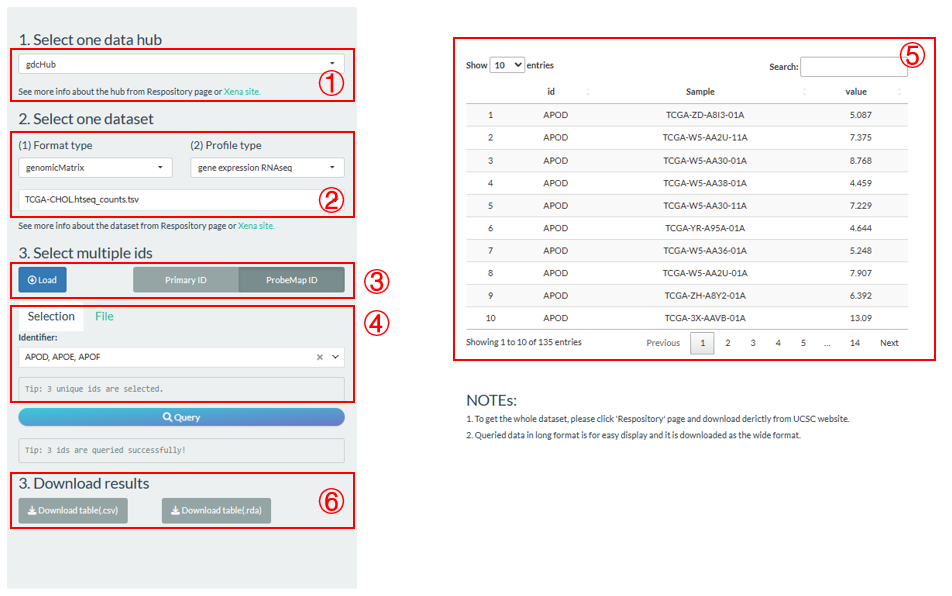
Figure 13.4: The steps of UCSC Xena dataset fetch