MySQL是一个常用的数据库管理系统,关于数据库可以简单理解多个有关联的二维表组成。
其中SQL(Structured Query Language)指操作关系型数据库的编程语言。
特点(1)关键字不区分大小写;(2)分号; 作为语句结束标志
笔记主要参考资料:【黑马程序员 MySQL数据库入门到精通,从mysql安装到mysql高级、mysql优化全囊括】的基础入门部分 https://www.bilibili.com/video/BV1Kr4y1i7ru?share_source=copy_web&vd_source=6edf13733e01570d1376e8b5e1ccbd6e

一、安装与用户管理
1、在centos7 linux系统中安装mysql [上述教学视频中为window安装],需要ROOT权限。
https://www.hostinger.in/tutorials/how-to-install-mysql-on-centos-7
在安装过程中遇到的注意事项
- 如果之前已经安装,需要卸载干净之前的记录,参考https://learnku.com/articles/35042
- 其中遇到
公钥尚未安装的问题解决报错,参考Centos7 yum安装的时候遇到公钥尚未安装的问题解决_张志翔 ̮的博客-CSDN博客解决 - 初次修改密码需要包含数字、字符、大小写,且长度大于8;可在之后修改密码强度要求等级。https://stackoverflow.com/questions/43094726/your-password-does-not-satisfy-the-current-policy-requirements
|
|
2、创建新用户
|
|
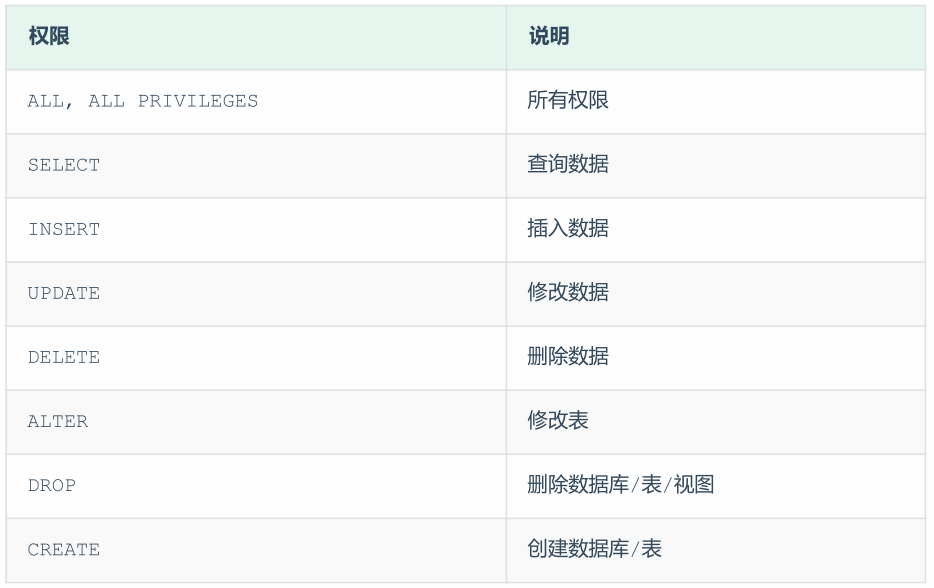
二、数据查询与操作
1、database基础操作
|
|
2、table表基础操作
|
|
3、创建表以及列修改
- 创建一张表的关键是交代每一列(字段)的名字、数据类型等。其中常见的数据类型包括
整型:int
小数:float,float(4, 1)
定长字符串:char, char(3)
变长字符串:varchar, varchar(10)
日期:date – 年月日
null为特使的数据类型,表示空值
|
|
4、行内容(表数据)修改
|
|
5、创建示例数据
|
|
6、数据常用查询
|
|
7、统计与分组统计
常用统计函数
count() 行数
avg(), max(), min(), sum()
|
|
8、常用函数与语句
|
|
9、连接两张表
|
|
10、嵌套查询
- 条件语句中的阈值/候选值由嵌套的另一个select语句间接确定
|
|
11、主键与外键
-
主键(primary key):具有表的唯一标识符的一列数据,一张表只能有一个主键。
外键(foreign key): 其中的一列数据含义与另一张表的主键相同时,可视为外键。
-
定义两张表的外键关系时,外键所在表称为子表,另一张表称为父表。
如上示例数据中,员工表(子表)的dept_id列与部门表(父表)的id列含义相同,可建立外键关系。
|
|
三、数据导出与导入
1、数据导出
- 导出表为txt或者csv文件
|
|
- 导处数据库/表为.sql文件(需要退出mysql,在shell界面完成)
|
|
2、数据导入
- 导入本地表文件至数据库的某个表里,注意导入时列顺序需要相同。
由于无法直接从默认目录读取ERROR 13 (HY000): File '/var/lib/mysql-files/tmp.txt' not found (OS errno 13 - 权限不够)。可以将待读取文件放到mysql所支持的/tmp/临时文件夹
|
|
|
|
- 导入本地sql至数据库中
|
|
|
|
补
1、修改sql数据库位置:https://www.tecmint.com/change-default-mysql-mariadb-data-directory-in-linux/
|
|
四、Chembl数据库实战
关于Chembl数据库:https://www.ebi.ac.uk/chembl/
Chembl数据库SQL下载:https://ftp.ebi.ac.uk/pub/databases/chembl/ChEMBLdb/latest/
文件大小—压缩包1.6G;解压缩后—15G;读入至SQL—33G
- 首先读入至mysql中
|
|
- (1)实验对应的靶点信息
|
|
- (2)化合物ID对应靶点的实验结果
|
|
- (3) 查询PubChemID对应的CHEMBL的化合物实验信息
|
|