1、html基础与xpath语法#
1.1 html基础#
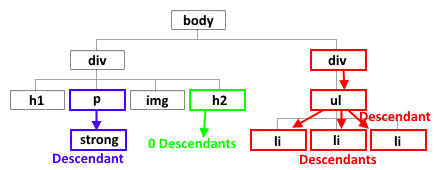
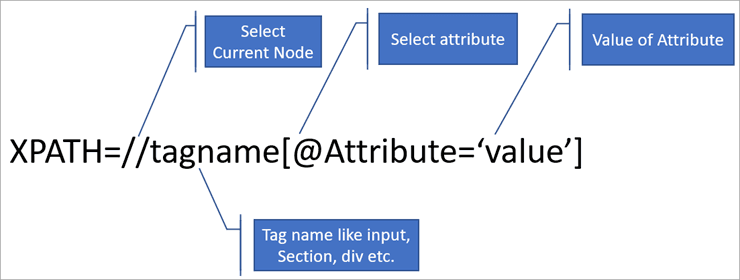
1.2 xpath语法#
2、xpath工具推荐#
2.1 浏览器自带的定位功能#
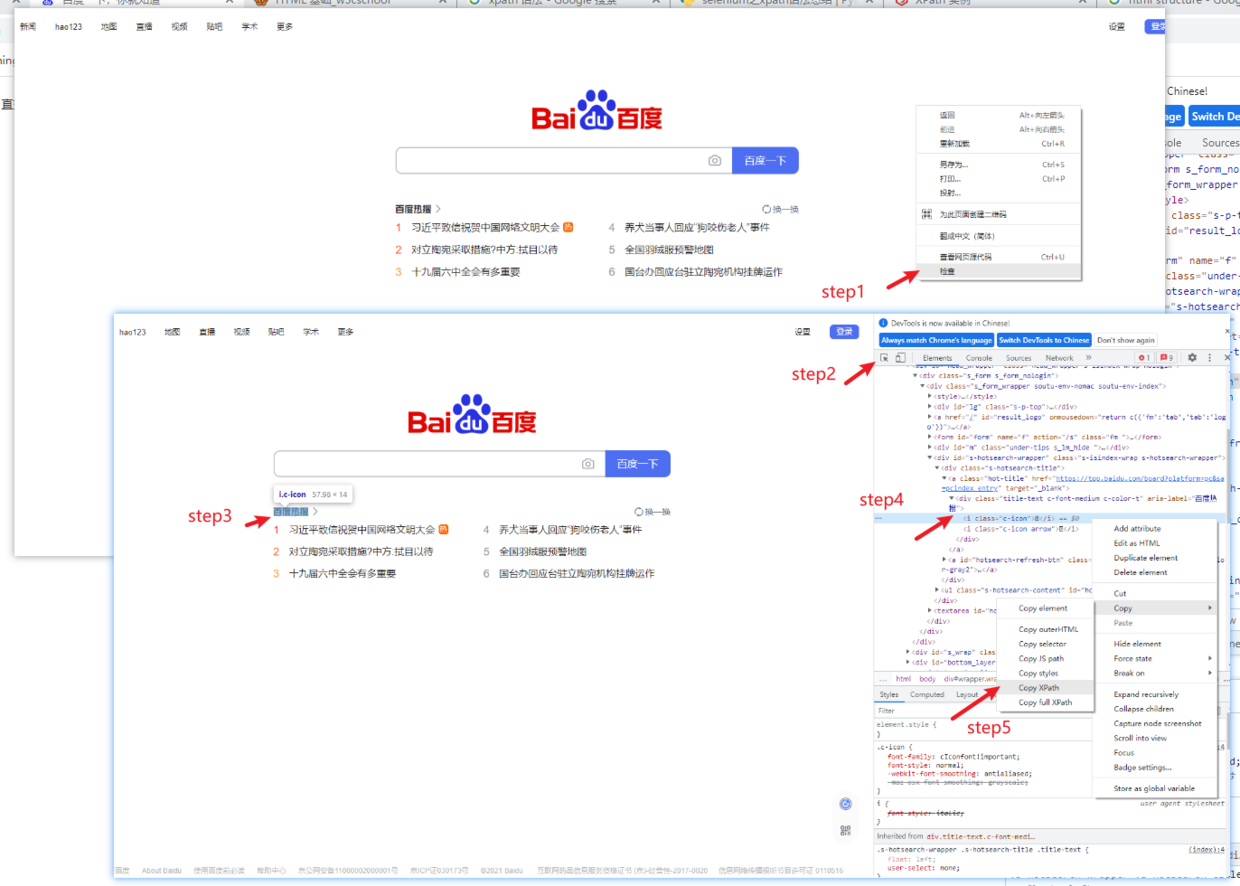
- 打开目标网页→ 右键单击“检查”→点击审查元素窗口左上角箭头→网页界面选择感兴趣内容→选中元素窗口高亮部分→右键单击,选择copy xpath
- 在元素窗口,使用ctrl+F快捷键,可以不断调试xpath
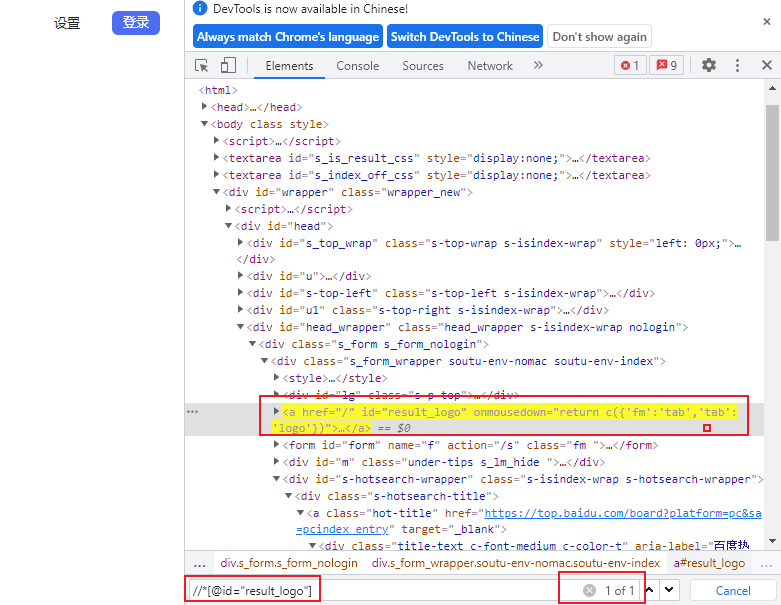
2.2 google插件之XPath Helper#
- 可以用来非常方便地调试、验证我们的xpath
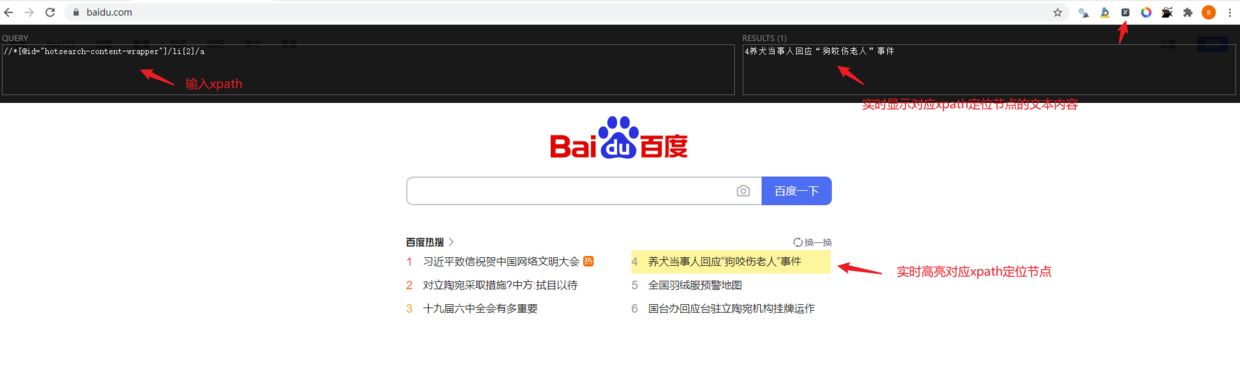
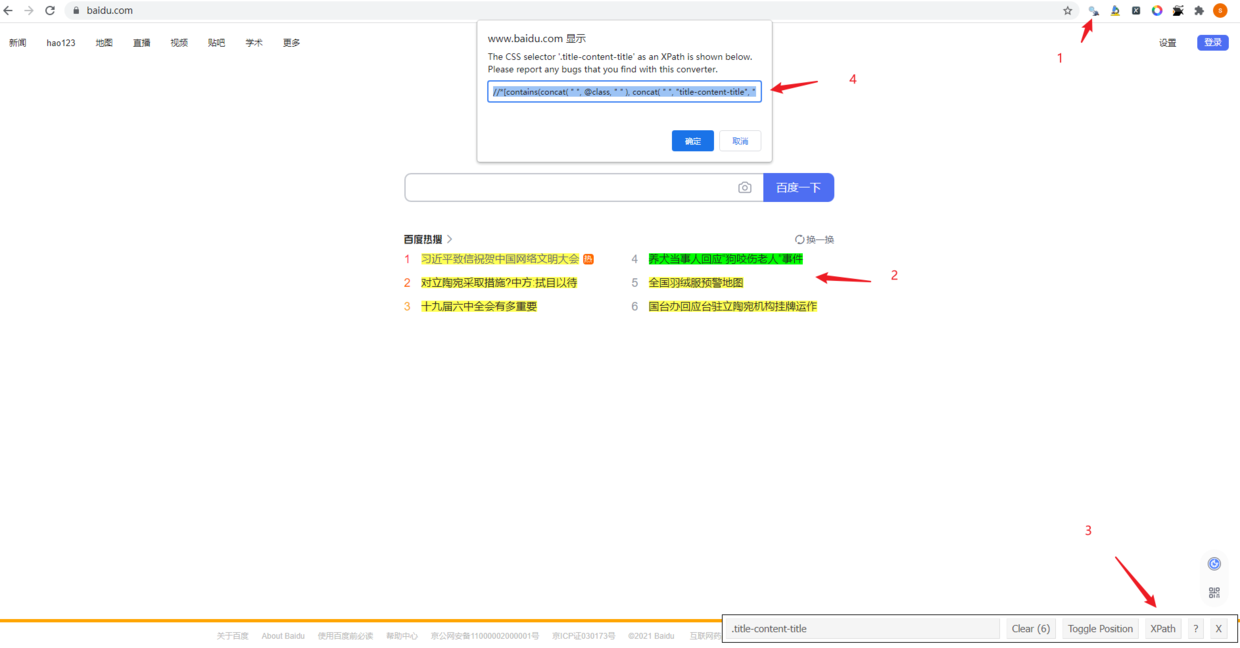
2.3 google插件之SelectorGadget#
- 该插件只需要我们在网页选择好感兴趣的标签,然后会自动生成能够定位到目标节点的xpath路径;
- 不过有一个缺点就是:SelectorGadget生成的xpath路径一般比较复杂,如果我们自己花心思调试一下(2.1)往往会生成简洁的xpath路径【通往罗马的道路不止一条】
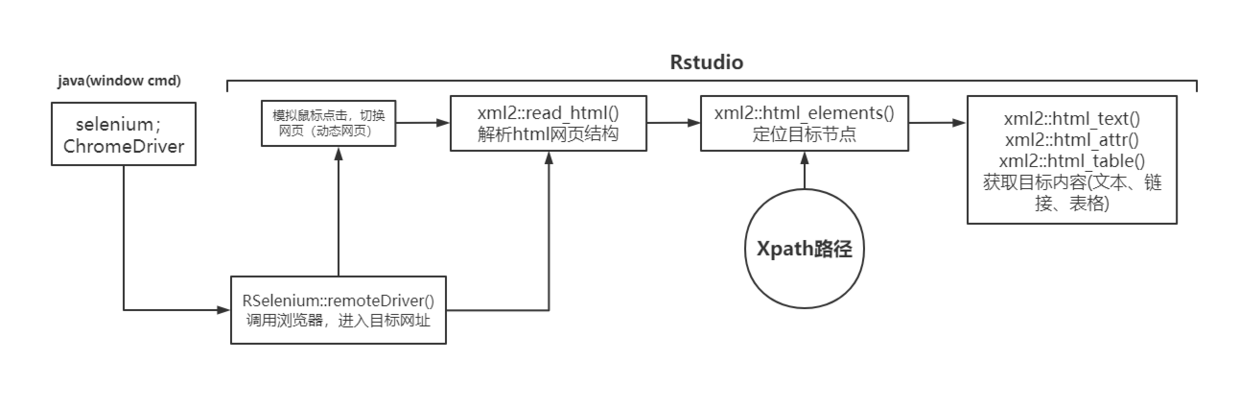
3、R语言爬虫流程#
一开始学习R语言爬虫时,直接xml2::read_html()对提交的网址进行解析,但经常会出现提交正确的xpath路径,但是没有提取到节点内容的尴尬结果{xml_nodeset (0)}。
后来了解到针对动态网页的selenium爬取方法,尝试了一下果然可以得到预期的结果。而且我觉得动静态网页通吃,因此以后的R语言爬虫都采用下述的流程来操作。
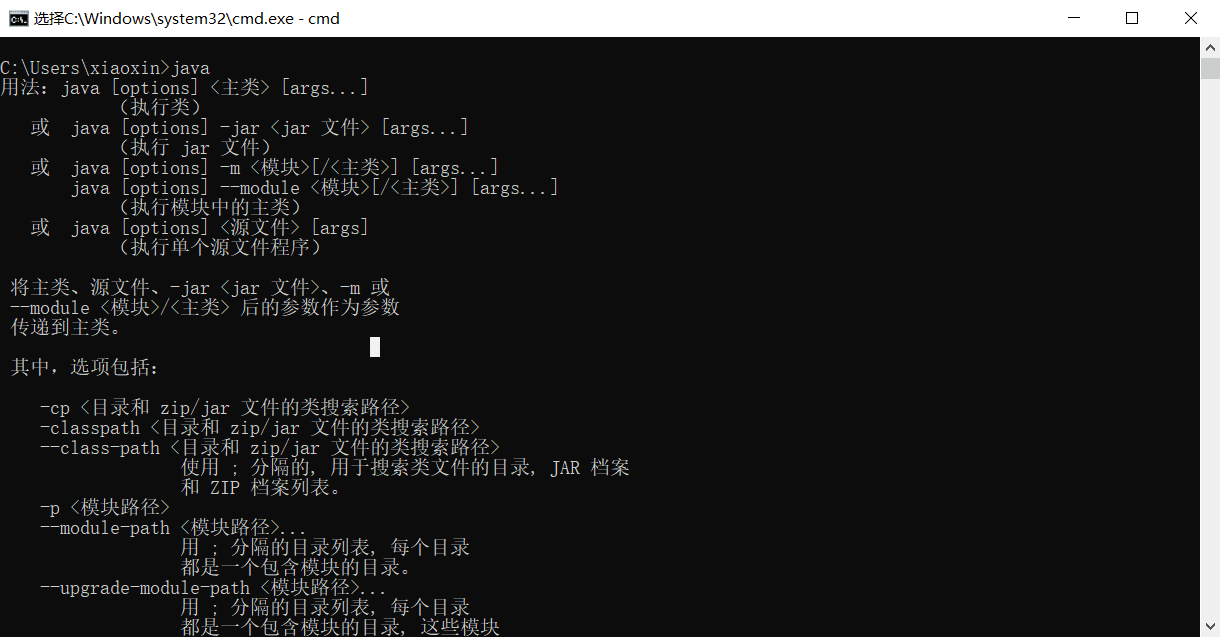
4、selenium相关配置(window) ⭐#
参考笔记:https://zhuanlan.zhihu.com/p/24772389
step1:安装Java#
step2:chrome浏览器相关#
step3:下载selenium-server-standalone.jar#
- 下载地址:http://selenium-release.storage.googleapis.com/index.html
有很多版本可供选择,我下载的是3.14版本;同时为了管理方便,与上面文件放在了同一文件夹内;
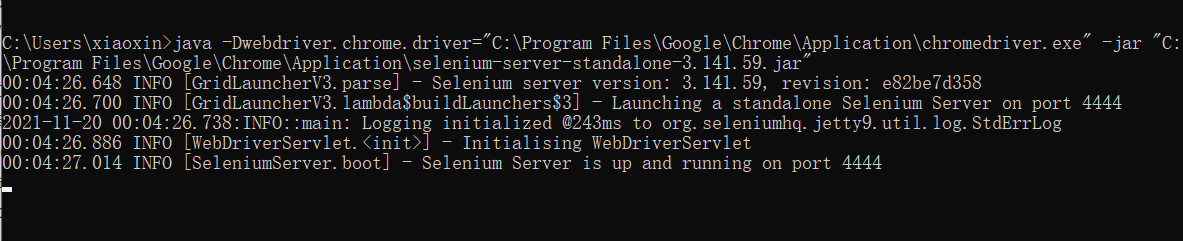
最后如果调用下面命令,出现如下图的结果说明selenium相关环境都配置好了
1
|
java -Dwebdriver.chrome.driver="C:\Program Files\Google\Chrome\Application\chromedriver.exe" -jar "C:\Program Files\Google\Chrome\Application\selenium-server-standalone-3.141.59.jar"
|
5、豆瓣爬虫实战#
前期准备#
(1)准备selenium环境#
- 打开window命令行界面:win + r ,输入
cmd回车;然后输入以下命令。待成功出现上图结果后,最小化界面即可。之后的操作都基于R
1
|
java -Dwebdriver.chrome.driver="C:\Program Files\Google\Chrome\Application\chromedriver.exe" -jar "C:\Program Files\Google\Chrome\Application\selenium-server-standalone-3.141.59.jar"
|

(2)安装、加载R包#
1
2
3
4
5
6
|
library(RSelenium) #调试浏览器
library(xml2) #解析html结构
library(rvest) #结合xpath,定位目标节点
library(tidyverse) #数据整理、清洗
|
实战1:爬取最近热门电影的名字、评分#
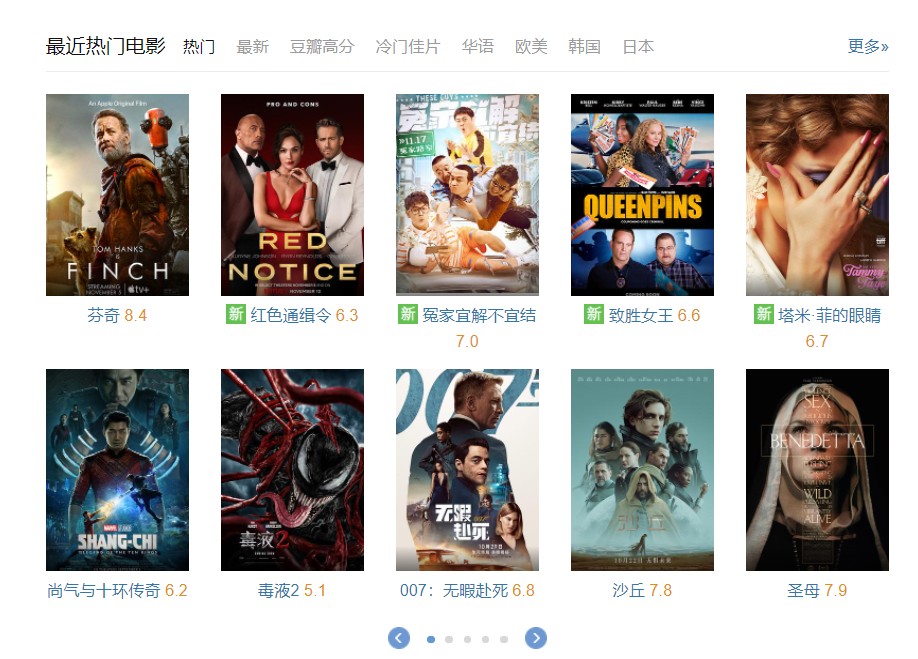
- 网址链接:https://movie.douban.com/
- 目标i节点的xpath路径:
//*[@id="content"]/div/div[2]/div[4]/div[3]/div/div[1]/div//p

Step1:调用浏览器,进入目标网址#
1
2
3
4
|
remDr <- remoteDriver(remoteServerAddr = "localhost",
port = 4444, browserName = "chrome")
remDr$open() # 打开浏览器
remDr$navigate("https://movie.douban.com") #进入网址
|
Step2:获得、解析当前网页html内容#
1
|
webpage <- read_html(remDr$getPageSource()[[1]][1]) #获得网页的html内容
|
Step3:应用xpath路径,定位、获取目标节点内容#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
xpath_name = '//*[@id="content"]/div/div[2]/div[4]/div[3]/div/div[1]/div//p'
text_raw = html_elements(webpage, xpath = xpath_name) %>% html_text()
str(text_raw)
# chr [1:70] "\n \n\n 致命感应\n\n \n 6.8\n \n " ...
#运用各种字符处理技巧,清洗数据
text_fine = text_raw %>% gsub(" ","",.) %>%
str_split("\n{2,}",simplify = T) %>% .[,2:3] %>%
as.data.frame() %>% rename(Name=V1, Score=V2)
head(text_fine)
# Name Score
# 1 致命感应 6.8
# 2 密室逃生2 6.2
# 3 健听女孩 8.6
# 4 普吉岛的最后黄昏 9.0
# 5 X特遣队:全员集结 8.0
# 6 灵媒 6.4
|
关于目标节点的xpath路径确认是很关键的一。其次当xpath路径本身含有双引号时,创建字符串时两边要改到单引号。
实战2:爬取最近热门电影的图片、详情页链接#
- 爬取图片时本质上还是获得图片对应的链接,然后再下载即可。
- 而链接内容一般作为节点的属性值,而不会在网页显示出来。
html_attr()可获得目标节点的属性值- 图片节点xapth:
//*[@id='content']/div/div[2]/div[4]/div[3]/div/div[1]/div//div/img

(1)爬取图片#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
xpath_img = "//*[@id='content']/div/div[2]/div[4]/div[3]/div/div[1]/div//div/img"
img_link = html_elements(webpage, xpath = xpath_img) %>%
html_attr(name = 'src')
head(img_link)
# [1] "https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2672792129.jpg"
# [2] "https://img9.doubanio.com/view/photo/s_ratio_poster/public/p2729074424.jpg"
# [3] "https://img2.doubanio.com/view/photo/s_ratio_poster/public/p2665001891.jpg"
# [4] "https://img9.doubanio.com/view/photo/s_ratio_poster/public/p2652268085.jpg"
# [5] "https://img2.doubanio.com/view/photo/s_ratio_poster/public/p2637084112.jpg"
# [6] "https://img2.doubanio.com/view/photo/s_ratio_poster/public/p2661923862.jpg"
#批量下载图片
#获取属性名为 src 的值
dir.create('tmp')
for (i in 1:length(img_link)) {
# i = 1
print(i)
img_name <- paste0('tmp/',text_fine$Name[i],".jpg")
download.file(url = img_link[i],
destfile = img_name,
method = "curl")
}
|
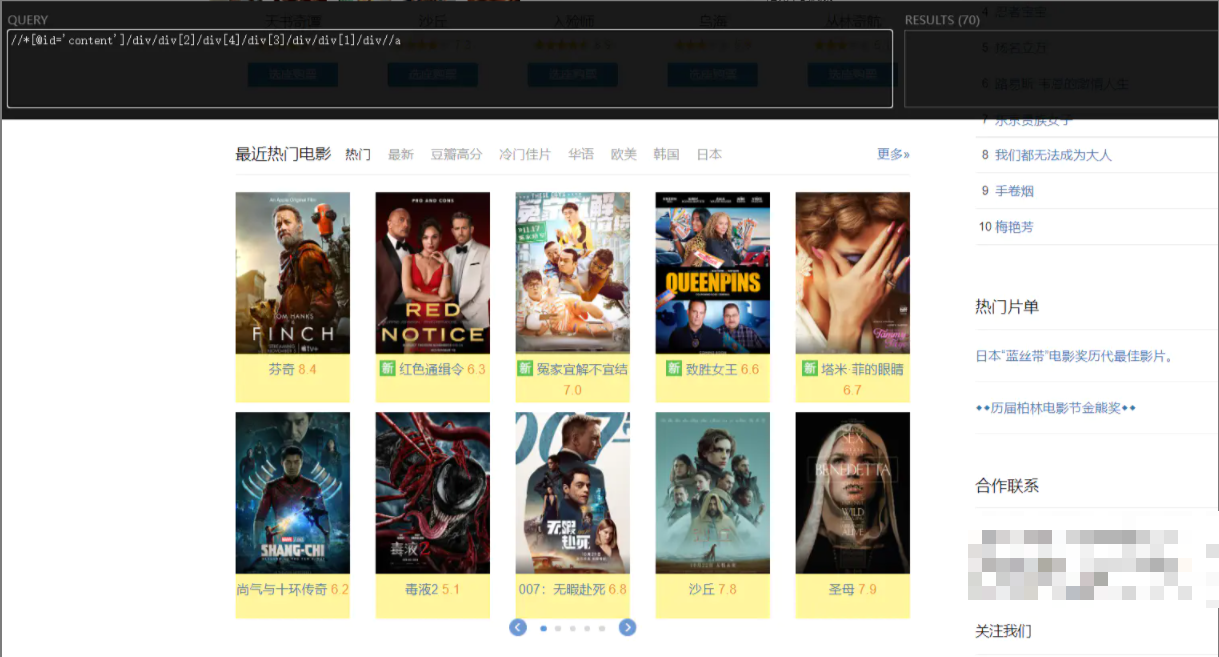
- 由于可以通过点击电影名进入电影详情页,由此判定在电影名节点的属性包含链接属性
- 电影名节点xapth:
//*[@id='content']/div/div[2]/div[4]/div[3]/div/div[1]/div//a
(2)爬取链接#
1
2
3
4
5
6
7
8
9
10
11
12
|
xpath_link = "//*[@id='content']/div/div[2]/div[4]/div[3]/div/div[1]/div//a"
movie_link = html_elements(webpage, xpath = xpath_link) %>%
html_attr(name = 'href')
movie_info = cbind(text_fine, movie_link)
head(movie_info)
# Name Score movie_link
# 1 致命感应 6.8 https://movie.douban.com/subject/25909236/?tag=热门&from=gaia_video
# 2 密室逃生2 6.2 https://movie.douban.com/subject/30469922/?tag=热门&from=gaia
# 3 健听女孩 8.6 https://movie.douban.com/subject/35048413/?tag=热门&from=gaia
# 4 普吉岛的最后黄昏 9.0 https://movie.douban.com/subject/35472124/?tag=热门&from=gaia
# 5 X特遣队:全员集结 8.0 https://movie.douban.com/subject/26741632/?tag=热门&from=gaia
# 6 灵媒 6.4 https://movie.douban.com/subject/35208823/?tag=热门&from=gaia
|
实战3:爬取不同类型标签的电影名、评分(模拟鼠标点击翻页)#
- Selenium的强大之处至于可以模拟鼠标操作进行网页选择、切换;
- 如下图,我们想获得框选出的8种类别的电影名与评分
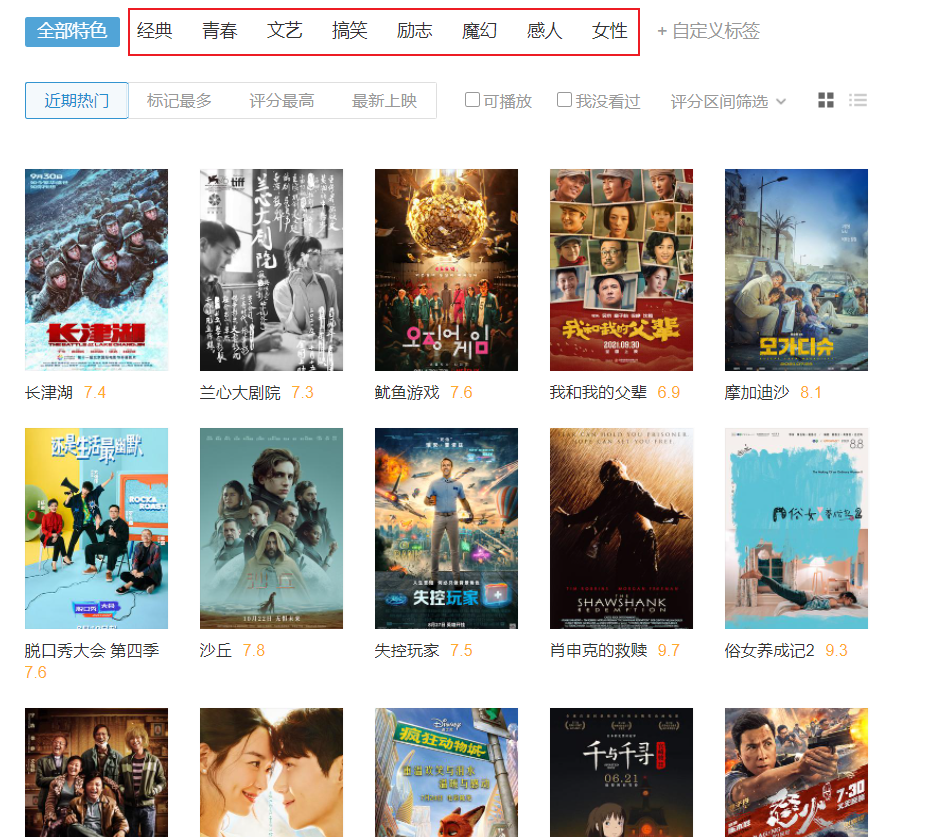
- 目标网址:
https://movie.douban.com/tag/#/
Step1:调用浏览器,进入目标网址#
1
2
3
4
|
remDr <- remoteDriver(remoteServerAddr = "localhost",
port = 4444, browserName = "chrome")
remDr$open() # 打开浏览器
remDr$navigate("https://movie.douban.com") #进入网址
|
Step2:获得、解析当前网页html内容#
1
|
webpage <- read_html(remDr$getPageSource()[[1]][1]) #获得网页的html内容
|
Step3:我们需要模拟鼠标点击那个节点、点多少次#
1
2
3
4
|
movie_type = webpage %>% html_elements(xpath = "//*[@id='app']/div/div[1]/div[1]/ul[5]//span") %>%
html_text() %>% .[2:9]
movie_type
# [1] "经典" "青春" "文艺" "搞笑" "励志" "魔幻" "感人" "女性"
|
Step4:循环点击、进行目标文本爬取#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
movie_stat = list()
for(i in seq(movie_type)){
# i=1
print(i)
#鼠标点击节点的xpath路径
button_xpath = sprintf("//*[@id='app']/div/div[1]/div[1]/ul[5]//span[contains(text(), '%s')]",
movie_type[i])
#该节点的鼠标点击属性
button = remDr$findElement(using ='xpath', value = button_xpath)
#模拟鼠标点击该节点
button$clickElement()
Sys.sleep(3)
#更新当前html内容
webpage <- read_html(remDr$getPageSource()[[1]][1])
xpath_name = "//*[@id='app']/div/div[1]/div[3]//span"
#结合目标文本的xpath路径爬取内容
test_raw = html_elements(webpage, xpath = xpath_name) %>% html_text()
movie_stat[[i]] = data.frame(Type = movie_type[i],
Name=test_raw[seq(2,60,3)],
Score=test_raw[seq(3,60,3)])
}
movie_stats = do.call(rbind, movie_stat)
head(movie_stats)
# Type Name Score
# 1 经典 沙丘 7.8
# 2 经典 肖申克的救赎 9.7
# 3 经典 我不是药神 9.0
# 4 经典 疯狂动物城 9.2
# 5 经典 千与千寻 9.4
# 6 经典 泰坦尼克号 9.4
table(movie_stats$Type)
# 感人 搞笑 经典 励志 魔幻 女性 青春 文艺
# 20 20 20 20 20 20 20 20
|
实战4:爬取表格结构的文本#
- 有时候我们的目标数据是以表格结构放在网页的;此时可直接利用
html_table()将表格爬取下来
- 示例网址:由于豆瓣网没有找到表格数据,因此切换到之前学过的记录疾病相关信息的网站https://www.malacards.org/card/alzheimer_disease?search=Alzheimer%20Disease
- 进入此网址,想对AD相关的基因信息进行爬取;
- xpath路径:
//*[@id="RelatedGenes-table"]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
remDr <- remoteDriver(remoteServerAddr = "localhost",
port = 4444, browserName = "chrome")
remDr$open() # 打开浏览器
remDr$navigate("https://www.malacards.org/card/alzheimer_disease?search=Alzheimer%20Disease") #进入分类网址
webpage <- read_html(remDr$getPageSource()[[1]][1]) #获得网页的html内容
xpath_test = '//*[@id="RelatedGenes-table"]'
test = webpage %>% html_elements(xpath = xpath_test) %>%
html_table()
df = test[[1]]
head(df)
# A tibble: 6 x 7
# `#` Symbol Description Category Score Evidence `PubMed IDs`
# <int> <chr> <chr> <chr> <dbl> <chr> <chr>
# 1 1 "APP" Amyloid Beta P~ "Protein~ 1408. "Molecular bas~ "1302033 1303239 ~
# 2 1 "APP::MIR1~ MIR106B Macro ~ "" NA "" ""
# 3 2 "HFE" Homeostatic Ir~ "Protein~ 1098. "Molecular bas~ "12429850 8696333~
# 4 3 "NOS3" Nitric Oxide S~ "Protein~ 708. "Molecular bas~ "9737779 9894802 ~
# 5 4 "MPO" Myeloperoxidase "Protein~ 696. "Molecular bas~ "11087769 1291567~
# 6 5 "PLAU" Plasminogen Ac~ "Protein~ 695. "Molecular bas~ "12898287 1561577~
|