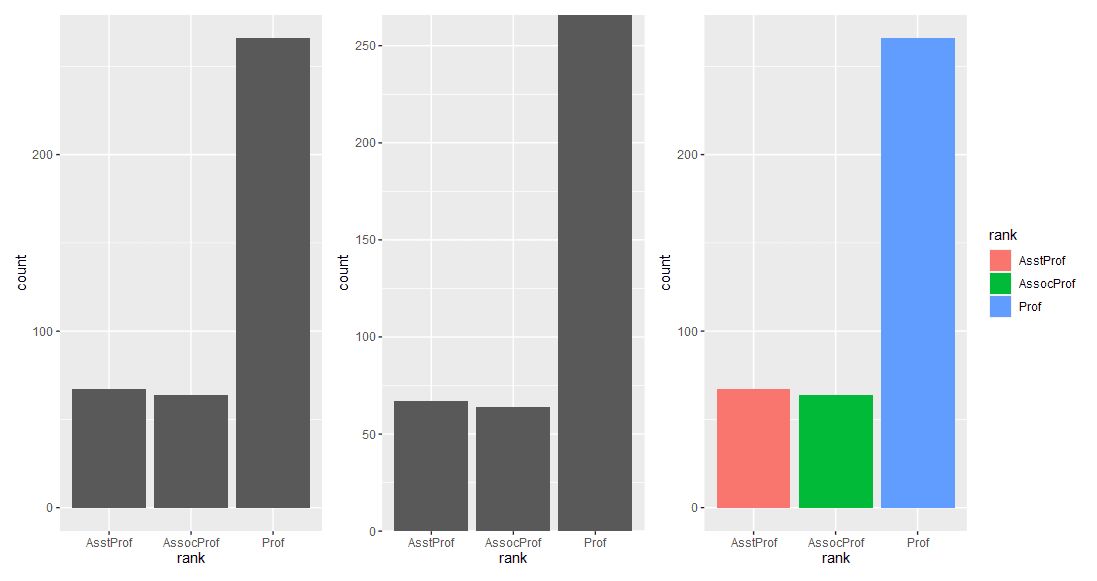
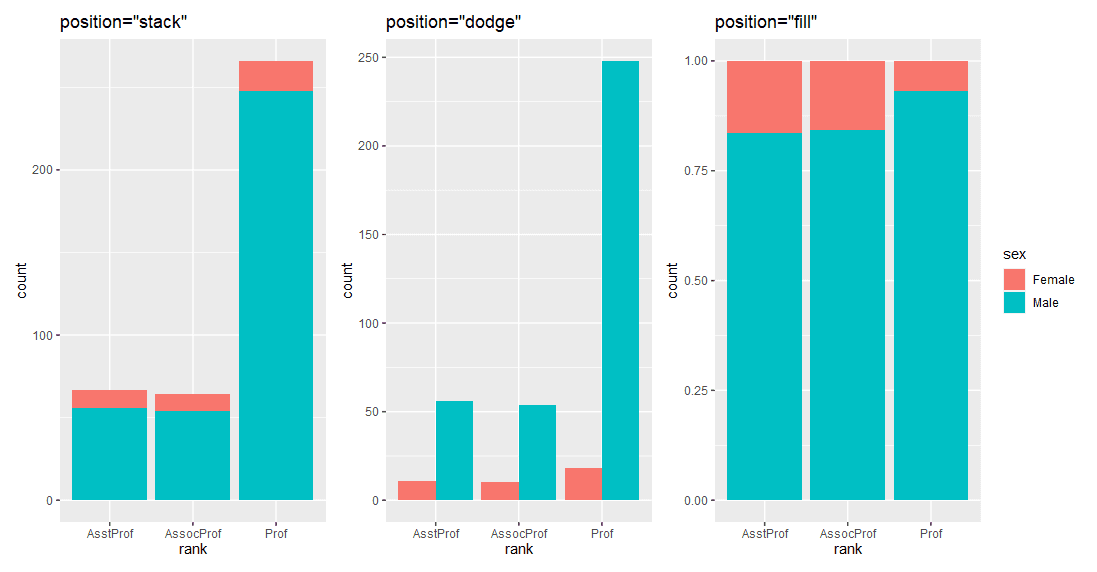
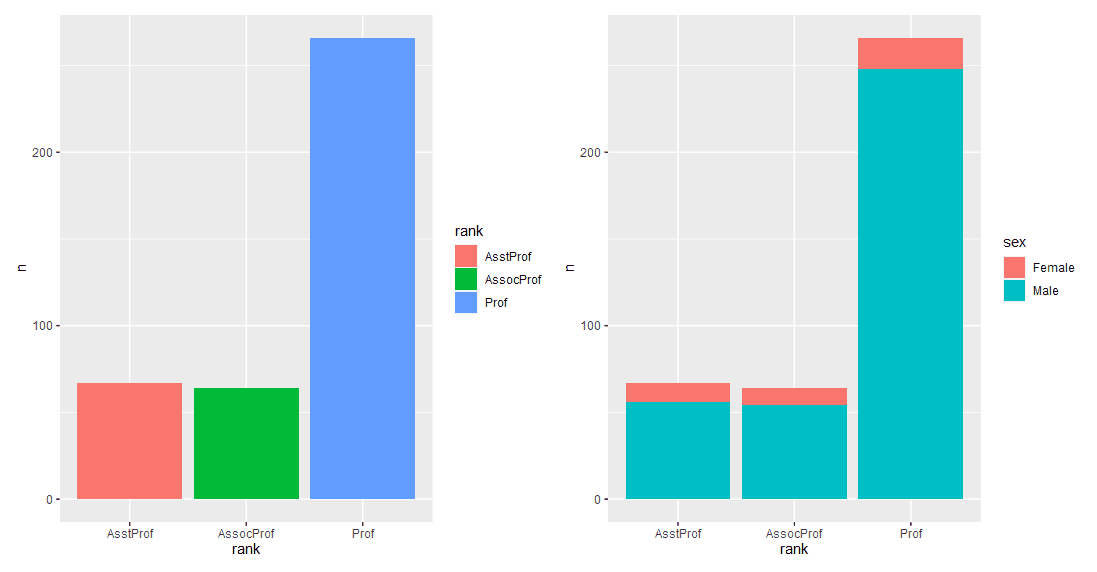
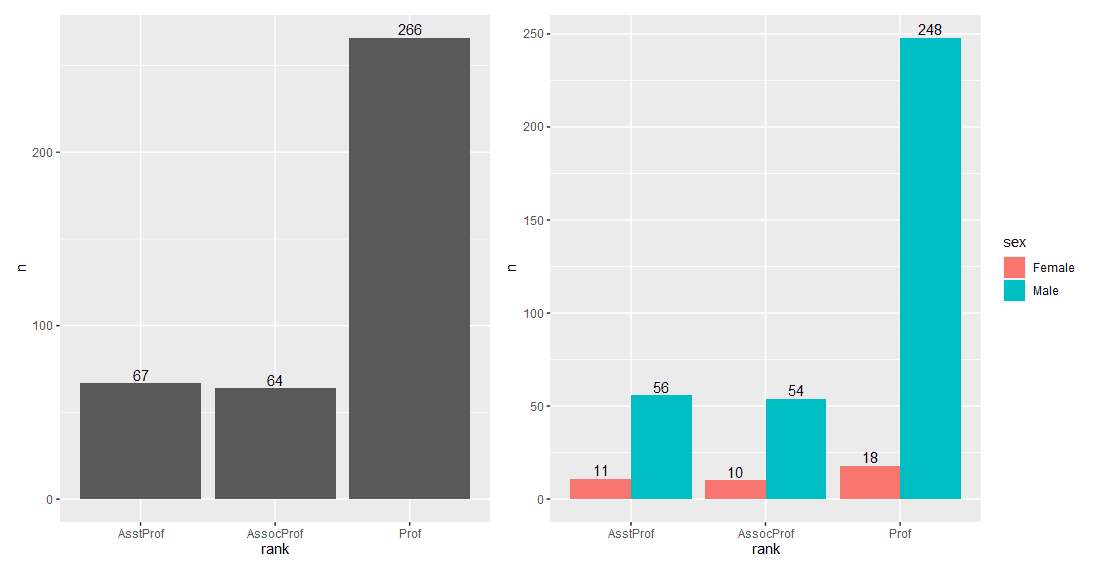
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
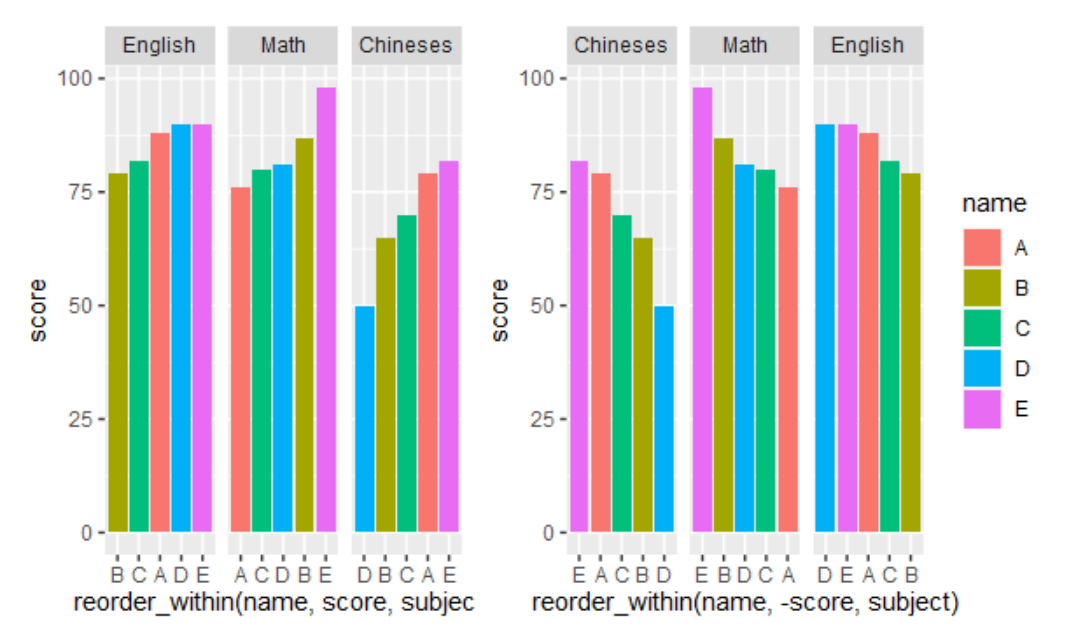
grade = data.frame(
subject=rep(c("Chineses","Math","English"), each=5),
name=rep(c("A","B","C","D","E"),3),
score=c(79,65,70,94,82,76,87,80,81,89,88,79,82,95,90))
# 先按学科均分从高到低
# 然后每个学科内,成绩从低到高学生排序
grade$subject=fct_reorder(grade$subject, grade$score, .desc=T)
library(tidytext)
p1 = ggplot(grade, aes(x=reorder_within(name,score,subject), y=score, fill=name)) +
geom_bar(stat = "identity") +
scale_x_reordered() +
facet_wrap(subject~. ,scales = "free_x")
# 先按学科均分从低到高
# 然后每个学科内,成绩从高到低学生排序
grade$subject=fct_reorder(grade$subject, grade$score, .desc=F)
library(tidytext)
p2 = ggplot(grade, aes(x=reorder_within(name,-score,subject), y=score, fill=name)) +
geom_bar(stat = "identity") +
scale_x_reordered() +
facet_wrap(subject~. ,scales = "free_x")
p1 + p2 + plot_layout(guides = 'collect')
|