lambda表达式可用于定义简单的一行式函数,并且可搭配其它函数时有多种衍生用法。
1、基础用法
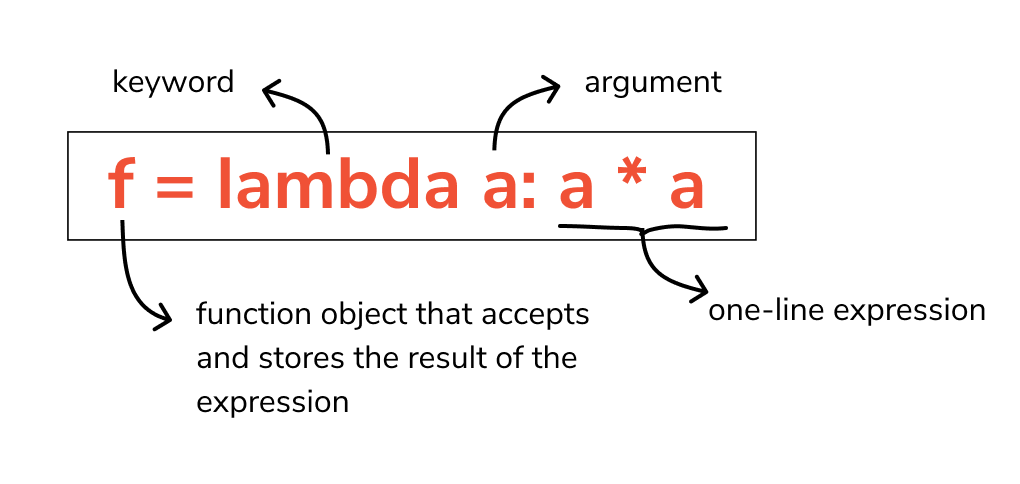
如下所示,lambda表达式有3个组分
- 关键字 lambda
- 函数所需的参数,根据需要可以有多个
- 函数表达式,通常就是一行。
|
|
2、搭配用法
2.1 map()迭代
map()接受两个参数:逐元素进行某个函数的计算,返回相应的结果
- 函数,可以使用简洁的lambda表达式
- 待迭代对象,例如列表
|
|
2.2 filter()筛选
map()同样接受两个参数:根据函数的计算的逻辑值结果判断是否保留元素(True)
- 函数,输出结果为逻辑值
- 待筛选对象,例如列表
|
|
2.3 pandas的apply()
- 类似R语言中的apply(), pandas表格的apply()函数可实现逐行,或者逐列操作
- 常用的还是逐行操作,例如根据表格已有列的值新增或者修改列。
- axis = 1 逐行操作 → 将表格的每一行作为参数传入函数 → 得到对应计算结果,变成一列值
|
|
上述使用lambda的地方都可改为传统的自定义函数,完成更加复杂的计算需求。