1. sys#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
##(1) sys.argv 给脚本传参
#如下定义一个sys.py脚本
#!/usr/bin/env python
import sys
print(sys.argv[0]) #第0个参数为脚本名
print(sys.argv[1])
python sys.py first
# sys.py
# first
##(2) sys.path 一个列表,包含要在其中查找模块的目录名称
sys.path.append()
|
2. os#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
## (1) os.system 执行shell命令
os.system("pwd")
os.system("ls -lh")
## (2) os.path 路径操作相关
os.path.abspath(".") #返回绝对路径
os.path.basename("/home/test/file.txt") #单独返回文件名
os.path.dirname("/home/test/file.txt") #单独返回路径名
os.path.split("/home/test/file.txt") #返回由文件名和路径名组成的元组
#('/home/test', 'file.txt')
os.path.splitext("file.txt") #将文件名与后缀名分开
#('file', '.txt')
os.path.exists("/home/test/file.txt") #判断文件或者目录是否存在
#False
## 此外os模块还支持对目录、文件的常规操作,例如创建、删除、重命名等
|
3. time#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
import time
time.sleep(3) #解释器等待指定秒数
time.time() #当前时间至新纪元的秒数(时间戳)
# 1649984110.885341
time.localtime() #默认返回当前时间戳的时间元组
time.localtime(100000000) #返回指定时间戳时间元组
# time.struct_time(tm_year=1973, tm_mon=3, tm_mday=3, tm_hour=17, tm_min=46, tm_sec=40, tm_wday=5, tm_yday=62, tm_isdst=0)
tuple(time.localtime(100000000)) # 返回tuple
# (1973, 3, 3, 17, 46, 40, 5, 62, 0)
###将时间元组格式化输出
time.asctime(time.localtime())
# 'Fri Apr 15 08:59:43 2022'
###(1)按自定义格式输出
#常见的item有: %Y-年, %m-月, %d-日, %H-时, %M-分, %S-秒, %a-星期几, %b-英文月份
#全部的item参考:https://www.runoob.com/python/python-date-time.html
time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
# '2022-04-15 09:12:29'
time.strftime("%a %b %d %H:%M:%S %Y", time.localtime())
# 'Fri Apr 15 09:12:49 2022'
###(2)将格式字符串转换为时间戳
a = "2022-04-15 09:12:29"
time.mktime(time.strptime(a,"%Y-%m-%d %H:%M:%S"))
# 1649985149.0
|
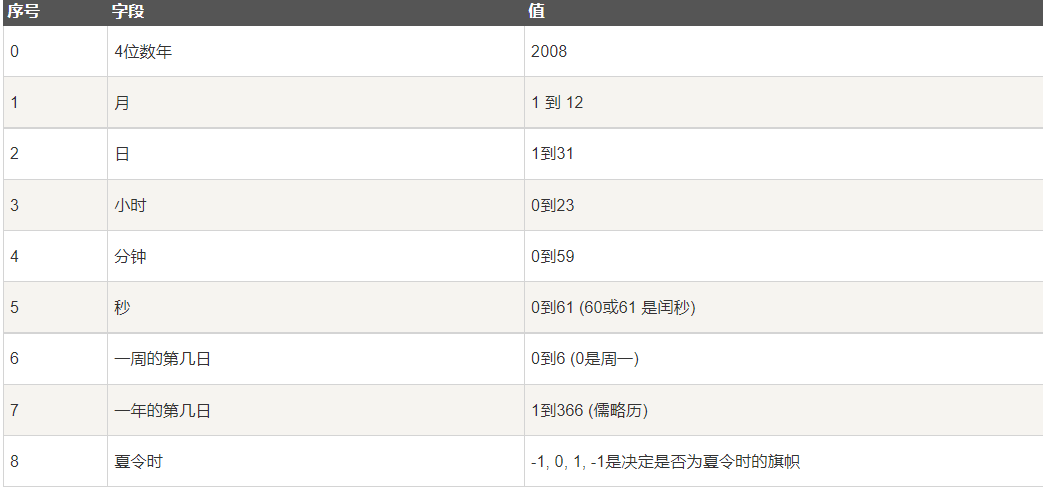
关于时间元组的格式:
4. random#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
from random import *
#(1)返回指定区间的一个随机实数
uniform(0,10)
#(2)返回指定区间的一个随机整数,注意不包含区间的上边界
randrange(1,5) #不会返回5
randrange(5) #默认为randrange(0, 5)
#(3)从给定序列中随机返回一个值,可以是列表、元组、字符串
choice([1,3,5,7])
#(4)从给定序列中随机返回n个不同的元素
sample(range(10),3)
# [3,5,6]
#(5)打乱给定序列的顺序
a = [1,3,5,7]
shuffle(a)
a
# [7, 5, 1, 3]
|
可通过设置随机种子random.seed(n),确保下一次抽样结果与先前相同种子的抽样结果相同。
5. re#
(1)正则表达式基础用法见之前的笔记
(2)尤其注意一点是:反斜杠\在正则表达式中视为转义符,可以将(1)特殊字符转为普通字符,例如\*表示匹配字符星号;(2)将普通字符转义为特殊字符,例如\d 表示匹配任一数字0-9
(3)由于python字符串也支持转义符,为避免混淆,当正则表达式中需要使用\时,十分建议使用r'正则表达式'的形式。所见即所得。
re.match():给定字符串的起始位置是否与正则表达式匹配
1
2
3
4
5
6
7
8
9
|
import re
re.match("p", "python")
# <re.Match object; span=(0, 1), match='p'>
print(re.match("p", "www.python"))
# None
print(re.match("w*", "www.python"))
# <re.Match object; span=(0, 3), match='www'>
|
re.match()返回的是一个MatchObject对象。当搭配使用圆括号时,可用于提取与指定正则部分匹配的子串,即成为编组group
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
site = 'www.123-456789.com'
m = re.match('www\.(\d*)\-(\d*)\.com', site)
## 编组0表示整个模式
m.group(0)
# 'www.123-456789.com'
## 之后编组的序号取决于左边括号树的编号
m.group(1) # '123'
m.group(2) # '456789'
## 括号镶嵌括号
re.match('www\.((\d*)\-(\d*))\.com', site).group(1)
# '123-456789'
## 编组子串的字符串位置索引
m.start(1) # 4
m.end(1) # 7
m.span(1) # (4, 7)
|
re.sub(): 将匹配的模式子串替换为指定的文本
1
2
3
4
5
6
|
import re
# re.sub(正则模式,新子串, 原始字符串)
phone = "2004-959-559 # 这是一个国外电话号码"
# 删除字符串中的 Python注释
re.sub(r' #.*$', "", phone)
# '2004-959-559'
|
1
2
3
4
|
import re
some_words = "aaaa,,,bbb++++ccc---dd"
re.split(r'[,\+\-]+', some_words)
# ['aaaa', 'bbb', 'ccc', 'dd']
|
re.findall: 返回给定字符串中所有匹配的子串
1
2
3
4
5
6
7
8
9
10
|
import re
some_words = "aaaa,,,bbb++++ccc---dd"
re.findall(r'\w+', some_words)
# ['aaaa', 'bbb', 'ccc', 'dd']
re.findall('[a-z]+', some_words)
# ['aaaa', 'bbb', 'ccc', 'dd']
re.findall(r'[,\+\-]+', some_words)
# [',,,', '++++', '---']
|
re.search() 寻找给定字符串中第一个匹配的子串,并且返回的是上述提到的MatchObject对象。
re.compile(): 将正则表达式转换为模式对象,以实现高效匹配。适用于重复执行同一个正则匹配任务。
1
2
3
4
5
6
7
8
9
10
11
|
#例如上面的例子
import re
regex = re.compile(r'\w+')
##可以看到上面提到的函数,都可以应用
[n for n in dir(regex) if not n.startswith("_")]
# ['findall', 'finditer', 'flags', 'fullmatch', 'groupindex', 'groups', 'match',
# 'pattern', 'scanner', 'search', 'split', 'sub', 'subn']
some_words = "aaaa,,,bbb++++ccc---dd"
regex.findall(some_words)
# ['aaaa', 'bbb', 'ccc', 'dd']
|
6. typing#
从3.5版本开始,Python 为函数参数和返回值提供了类型注解的支持。
- 参数类型提示:使用
: 后跟类型来指定参数的类型。
- 返回值类型提示:使用
-> 后跟类型来指定返回值的类型。
基本类型包括: int, float, str, bool
1
2
|
def add(x: int, y: int) -> int:
return x + y
|
基于typing模块,定义容器类型, 包括 List, Tuple, Dict, Set等
Optional[str]: 表示字符串或者NoneUnion[int, str]: 表示整型或者字符串类型
1
2
3
4
5
6
7
8
9
10
11
12
|
from typing import List, Tuple, Dict
def sum_of_elements(numbers: List[int]) -> int:
return sum(numbers)
# 返回元组,由字符串和整数组成
def get_name_and_age() -> Tuple[str, int]:
return "Alice", 30
# 返回元组,有字典组成。每个字典的key是字符,值是张量
def get_complex_data() -> Tuple[Dict[str, torch.Tensor]]:
return "Alice", 30
|
7. pathlib#
Python 3.4 引入的一个模块,用于以面向对象的方式处理文件系统路径。
1
|
from pathlib import Path
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# 当前目录
current_path = Path('.')
# 指定路径
specific_path = Path('/path/to/directory')
# 拼接路径
new_file = current_path / "file.txt"
print(new_file.name) # 文件名
# 'file.txt'
print(new_file.stem) # 文件名不含扩展
# 'file'
print(new_file.suffix) # 文件扩展名
# 'txt'
print(new_file.parent) # 父目录
# PosixPath('.')
print(new_file.resolve()) # 绝对路径
new_file.resolve().parent.parent
|
1
2
3
4
5
6
7
8
9
10
11
|
if specific_path.exists():
print("Path exists")
if specific_path.is_file():
print("It's a file")
if specific_path.is_dir():
print("It's a directory")
new_dir = Path('new_directory')
new_dir.mkdir(exist_ok=True)
|
8. Enum#
- 在Python中,枚举类型是一种符号化的常量集合;
- 枚举类一旦在定义后,不可修改或增加新的枚举成员。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
from enum import Enum
# 定义一个枚举类
class Day(Enum):
MONDAY = 1
TUESDAY = 2
WEDNESDAY = 3
THURSDAY = 4
FRIDAY = 5
SATURDAY = 6
SUNDAY = 7
## (1)访问枚举成员
Day(1) # 通过成员的value访问
Day.MONDAY # 通过成员的name访问
## (2)枚举成员由name与value两部分组成
Day.MONDAY.name
# 'MONDAY'
Day.MONDAY.value
# 1
## (3)访问所有枚举成员
Day.__members__ # 不可修改的字典类型
# mappingproxy({'MONDAY': <Day.MONDAY: 1>,
# 'TUESDAY': <Day.TUESDAY: 2>,
# 'WEDNESDAY': <Day.WEDNESDAY: 3>,
# 'THURSDAY': <Day.THURSDAY: 4>,
# 'FRIDAY': <Day.FRIDAY: 5>,
# 'SATURDAY': <Day.SATURDAY: 6>,
# 'SUNDAY': <Day.SUNDAY: 7>})
Day._value2member_map_
# {1: <Day.MONDAY: 1>,
# 2: <Day.TUESDAY: 2>,
# 3: <Day.WEDNESDAY: 3>,
# 4: <Day.THURSDAY: 4>,
# 5: <Day.FRIDAY: 5>,
# 6: <Day.SATURDAY: 6>,
# 7: <Day.SUNDAY: 7>}
|
9. collections#
- Counter: 统计可迭代对象(e.g. list)的元素的频数
1
2
3
4
5
6
7
8
9
10
11
|
from collections import Counter
data = ["a", "b", "c", "b", "c", "b"]
freq = Counter(data)
# Counter({'b': 3, 'c': 2, 'a': 1})
freq["a"]
# 1
freq["b"]
# 3
|
- defaultdict: 访问不存在的键时,不会引发报错。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
from collections import defaultdict
# 创建一个defaultdict,默认值为0
d = defaultdict(int)
# 创建一个defaultdict,默认值为空列表[]
d = defaultdict(list)
print(d['key'])
# []
d
# defaultdict(list, {'key': []})
d["key"].append(10)
# defaultdict(list, {'key': [10]})
d["new_key"].append("aw")
# defaultdict(list, {'key': [10], 'new_key': ['aw']})
|
- OrderedDict:会记住元素插入的顺序,在迭代时,返回的元素顺序与插入时一致 (PS:Python>3.7版本也会默认支持)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
from collections import OrderedDict
# 创建一个OrderedDict
od = OrderedDict()
od['a'] = 1
od['b'] = 2
od['c'] = 3
# 遍历OrderedDict,元素顺序与插入顺序相同
for key, value in od.items():
print(key, value)
# a 1
# b 2
# c 3
|