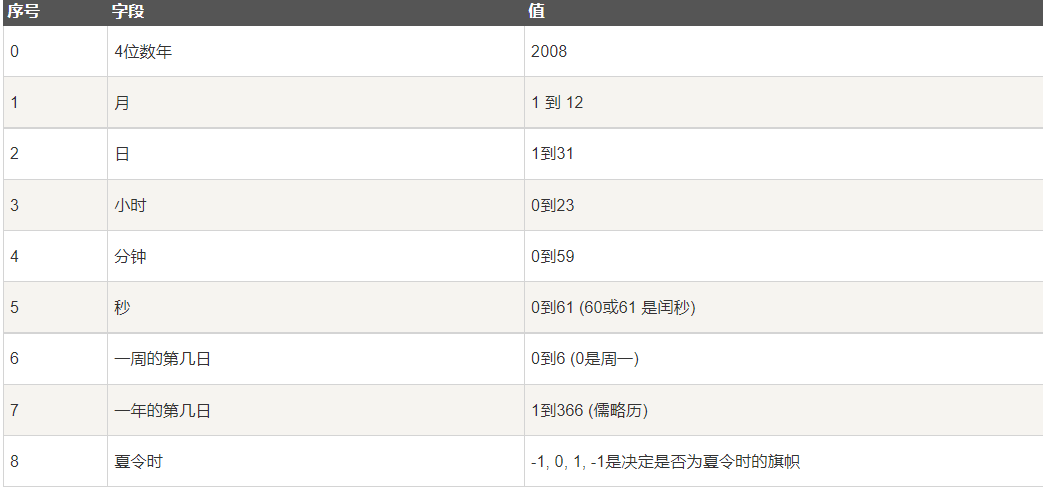
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
import time
time.sleep(3) #解释器等待指定秒数
time.time() #当前时间至新纪元的秒数(时间戳)
# 1649984110.885341
time.localtime() #默认返回当前时间戳的时间元组
time.localtime(100000000) #返回指定时间戳时间元组
# time.struct_time(tm_year=1973, tm_mon=3, tm_mday=3, tm_hour=17, tm_min=46, tm_sec=40, tm_wday=5, tm_yday=62, tm_isdst=0)
tuple(time.localtime(100000000)) # 返回tuple
# (1973, 3, 3, 17, 46, 40, 5, 62, 0)
###将时间元组格式化输出
time.asctime(time.localtime())
# 'Fri Apr 15 08:59:43 2022'
###(1)按自定义格式输出
#常见的item有: %Y-年, %m-月, %d-日, %H-时, %M-分, %S-秒, %a-星期几, %b-英文月份
#全部的item参考:https://www.runoob.com/python/python-date-time.html
time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
# '2022-04-15 09:12:29'
time.strftime("%a %b %d %H:%M:%S %Y", time.localtime())
# 'Fri Apr 15 09:12:49 2022'
###(2)将格式字符串转换为时间戳
a = "2022-04-15 09:12:29"
time.mktime(time.strptime(a,"%Y-%m-%d %H:%M:%S"))
# 1649985149.0
|