1. 背景#
DDP分布式训练与DP并行训练
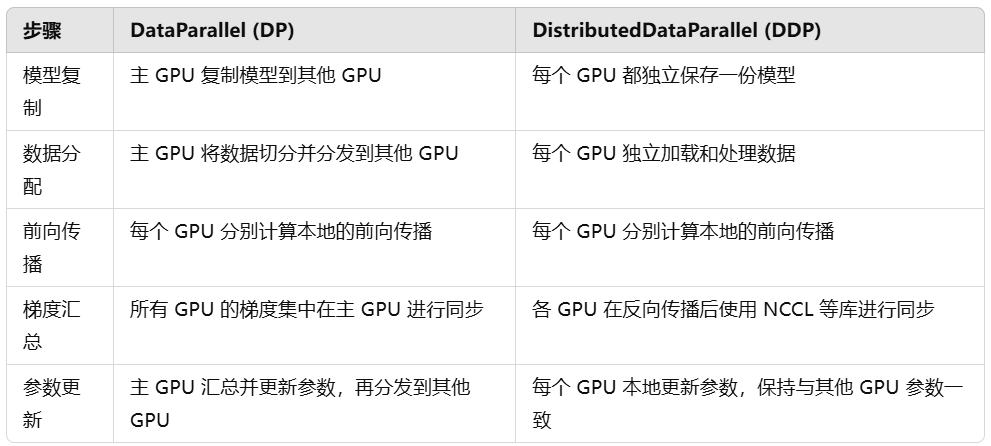
在之前了解多GPU训练时,学习过一种数据并行方式DataParallel (DP)。其核心将模型复制到每个 GPU,然后在每个 GPU 上分配一小部分数据并行执行计算。最后,主 GPU 汇总所有 GPU 的梯度并更新模型参数。实现角度也非常简单,使用nn.DataParallel()即可。
在实际场景中,另一种数据并行方式DistributedDataParallel (DDP)使用更加广泛。每个 GPU(进程)都有一个模型副本,各个副本只处理数据的一个子集。每个 GPU 都独立地进行前向和反向传播,之后所有 GPU 的梯度会同步,确保更新一致。
以Pytorch为例,其启用方式有很多种,下面学习基于torchrun的用法。
参考资料
- 网页教程:https://pytorch.org/tutorials/beginner/ddp_series_intro.html
- 教程视频:https://www.youtube.com/watch?v=-K3bZYHYHEA
- Github源码:https://github.com/pytorch/examples/tree/main/distributed/ddp-tutorial-series
2. 关键代码#
需要以脚本形式运行。在jupyter交互式环境无法使用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
## 加载Torch相关模块
import torch
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
# 分布式相关模块
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.distributed import init_process_group, destroy_process_group
import os
## 初始设置
# 单机训练时的GPU id
local_rank = int(os.environ["LOCAL_RANK"])
# 多机训练时的GPU 全局id
rank = int(os.environ["RANK"])
# 全部GPU的数量
world_size = torch.distributed.get_world_size()
torch.cuda.set_device(local_rank)
init_process_group(backend="nccl")
## 数据层面
# 分布式样本抽样(使得每个GPU获取样本没有重复)
train_sampler = DistributedSampler(train_dataset)
# 样本迭代器(由于train_sampler默认已经shuffle,所有这里不用设置shuffle)
train_loader = DataLoader(train_dataset,
batch_size=BATCH_SIZE,
shuffle = False,
sampler=train_sampler)
## 模型层面
model = MyModel()
# 如果模型有Batchnorm操作
model = nn.SyncBatchNorm.convert_sync_batchnorm(model)
model = model.to(local_rank)
model = DDP(model, device_ids=[local_rank])
## 训练时将小批量数据转移至GPU操作类似
for index, (data, labels) in enumerate(train_loader):
data, labels = data.to(local_rank), labels.to(local_rank)
print(f'[GPU {local_rank}] Epoch {epoch} | Step {index} is OK ---')
#其它需要转移GPU设置类似
## 结束DDT分布式训练
destroy_process_group()
|
1
2
|
# 单卡4 GPU训练
torchrun --standalone --nproc_per_node=4 torchrun_multigpu.py
|
3. 更多用法#
(1)如果模型model使用到batchnorm,需要使用同步操作。
1
2
3
4
|
model = MyModel()
model = nn.SyncBatchNorm.convert_sync_batchnorm(model)
model = model.to(local_rank)
model = DDP(model, device_ids=[local_rank])
|
(2)torch.distributed.barrier 确保所有进程在到达某个点时都等待其他进程,从而保证所有进程在继续执行下一步之前已经完成了当前的步骤。
1
2
3
4
5
6
7
8
|
# 模拟一些操作
print(f"Rank {rank} is working...")
# 假设这里有一些耗时的操作
# 同步所有进程: 阻塞当前进程,直到所有进程都到达这个调用点。
dist.barrier()
# 继续执行后续操作
|
(3)with model.no_sync() 减少通信开销,降低显存需求
- 在 DDP 中,默认情况下,每次前向传递和反向传递后,所有进程会同步梯度
- 使用
no_sync() 可以暂时禁用这种同步,允许你在多个小批次(micro-batches)中累积梯度,然后再进行一次同步。
- 假设实际批量大小为 16,且每 4 个批次进行一次梯度同步,等价于每次训练都使用 16 × 4 = 64 的等效批量大小。
1
2
3
4
5
6
7
8
9
10
11
|
for i, (inputs, labels) in enumerate(dataloader):
# 在 no_sync 下计算梯度,不同步
with model.no_sync():
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward() # 仅累积梯度,不进行同步
# 每 4 个批次同步一次
if (i + 1) % 4 == 0:
optimizer.step() # 更新权重
optimizer.zero_grad() # 清空梯度
|
(4)torch.distributed.reduce 模型汇总多个GPU的训练结果
- 使用场景:在分布式训练中,需在多 GPU 上计算损失或某种指标的平均值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
def get_reduced(tensor, current_device, dest_device, world_size):
"""
将不同GPU上的变量或tensor集中在主GPU上,并得到均值
"""
# 如果输入的是 tensor,则创建一个其拷贝并与计算图断开;否则将其转化为 tensor。
tensor = tensor.clone().detach() if torch.is_tensor(tensor) else torch.tensor(tensor)
# 将 tensor 移动到当前设备
tensor = tensor.to(current_device)
# 使用 torch.distributed.reduce 将当前设备的 tensor 发送到目标设备(dest_device)上
torch.distributed.reduce(tensor, dst=dest_device)
# 在目标设备上将 tensor 值取平均
tensor_mean = tensor.item() / world_size
return tensor_mean
# 计算每个GPU训练的平均loss
epoch_loss = get_reduced(epoch_loss, local_rank, 0, world_size)
|