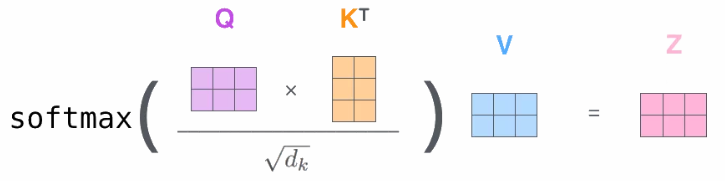
注意力计算
- 注意力计算的三要素分别是:Query, Key,Value。而在自注意力计算中,三者则是等价的。
- 结合如下图示例:一个序列有2个词元,每个词元有3个特征 ,即输入为(2, 3)
- 每个Query词元会计算与其它词元Key的“相似度”(包括自己),再经过softmax(每行的和等于1)转换,得到 2 × 2 权重矩阵
- 然后将其与Value矩阵进行乘法运算(2, 2) × (2, 3),得到新的(2, 3)输出结果
- 形象理解:对于词元A的输出特征1,等于输入词元A, B的特征的加权和。
- 多头注意力:本质上可以理解为将特征维度分成多个部分,每个部分称为一个“头”。每个头独立进行注意力计算,然后将所有头的输出合并在一起;以期学习不同的关系和模式。
- 注意力计算本身不涉及可学习参数。一般在input前,out后,各设置一层MLP线性变换。
参考:https://blog.csdn.net/God_WeiYang/article/details/131820781
0. 模拟数据
-
通常情况下,注意力计算的输入数据拥有四个维度:(batch_size, num_heads, seq_length, head_dim)
word embed = num_heads × head_dim
|
|
最终词元的特征长度为:num_heads × head_dim
1. 手动Attention计算
- causal参数表示注意力掩码操作,常用于GPT生成模型中。表示计算序列中第n个词元时,只关注第1到n-1个(除了本身);
- 具体通过
torch.finfo(q.dtype).min设置为负无穷,则其softmax转换后的权重值为0。
|
|
2. Flash Attention 1/2
- Flash Attention 一种高效的注意力计算方法,旨在优化 Transformer 模型中的注意力机制。它通过减少内存使用和提高计算速度来处理长序列输入。
- https://github.com/Dao-AILab/flash-attention
2.1 安装
- 之前学习的scGPT主要使用了FlashAttention-1,安装方法见之前的整理
|
|
- 本次主要学习FlashAttention-2版本 (with Better Parallelism and Work Partitioning)。安装过程踩了很多坑,目前找到一种可信的方式。
|
|
非本地安装方式为:
1 2 3 4 5pip install ninja #加速build安装进程,实测发现只对下面的clone安装有作用 pip install flash-attn --no-build-isolation # or clone github repo python setup.py install由于是在conda环境下安装的cuda,所以在上述过程中会出现类似
cuda_runtime_api.h: No such file or directory的报错。查了很多教程,比较靠谱的方法是安装cudatoolkit-dev。这同时带来一个问题,目前其最高版本为11.7,需要安装与之对应的cuda环境,以及torch等
1 2 3 4 5mamba install -c conda-forge cudatoolkit-dev mamba install cudatoolkit==11.7 -c nvidia mamba install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.7 -c pytorch -c nvidia python setup.py install
2.2 使用
- 输入维度要求一般是:(batch_size, seqlen, nheads, headdim)
|
|
3. F.scaled_dot_product_attention
torch.nn.functional.scaled_dot_product_attention是torch2.0版本更新后,新增的注意力加速计算方法- 其采用了包括Flash-attention2在内的三种加速算法
- FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
- Memory-Efficient Attention
- A PyTorch implementation defined in C++ matching the above formulation
- All implementations are enabled by default. Scaled dot product attention attempts to automatically select the most optimal implementation based on the inputs
|
|
4. Benchmark
|
|
- 定义函数,测试注意力计算的时间以及显存消耗
|
|
- 测试不同序列长度,三种计算时间以及显存消耗情况
- (1)序列的长度越长时,pytorch func与flash attention计算优势越明显
- (2)pytorch func与flash attention的差距不太明显。
|
|
- 测试不同特征长度,三种计算时间以及显存消耗情况
- 词元的特征维度越大时,pytorch func与flash attention计算优势会逐渐下降。
|
|
5. nn.MultiheadAttention及mask操作
torch.nn.MultiheadAttention
https://pytorch.org/docs/stable/generated/torch.nn.MultiheadAttention.html
- torch 实现的标准多头注意力层类,包含完整输入与输出的权重参数
|
|
默认need_weights = True,即返回多头注意力矩阵计算结果。如果设置为False,use the optimized
scaled_dot_product_attentionand achieve the best performance for MHA.
前向计算的mask相关参数
key_padding_mask:用于标记一个序列中的pad填充字符,使得query不会关注与其的注意力。
- 其shape通常是 (Batch_size, Seq_len)。
- True表示是pad填充字符
|
|
attn_mask:注意力掩码矩阵,直接对特定的query-key组合进行掩码操作
- 其shape通常是(Batch_size*Num_head, Seq_len, Seq_len)
- True表示特定注意力被掩码
- 与key_padding_mask最终mask的效果是相同的。如下演示如何将key_padding_mask转换为attn_mask,得到一致的输出结果。
- https://stackoverflow.com/questions/62629644/what-the-difference-between-att-mask-and-key-padding-mask-in-multiheadattnetion
|
|
关于上述key_padding_mask的转换有如下值得注意的细节。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20mask = torch.randn(3, 4) # (Batch_size, Seq_len), num_head = 2 ## 直接repeat不是所期望的结果 mask.unsqueeze(1).repeat(2,1,1) # repeat all batch as whole and cannot match the multi-head # tensor([[[ 0.5375, 1.3711, -0.3028, 1.0184]], # [[-0.1414, 1.3067, -0.0363, 0.8482]], # [[ 0.3573, -0.9005, -0.3998, -0.8608]], # [[ 0.5375, 1.3711, -0.3028, 1.0184]], # [[-0.1414, 1.3067, -0.0363, 0.8482]], # [[ 0.3573, -0.9005, -0.3998, -0.8608]]]) ## 如下两种方式均是符合预期的转换 mask.unsqueeze(1).unsqueeze(2).expand(3, 2, 1, 4).reshape(6, 1, 4) # repeat each seq two multi-head (expected) # tensor([[[ 0.5375, 1.3711, -0.3028, 1.0184]], # [[ 0.5375, 1.3711, -0.3028, 1.0184]], # [[-0.1414, 1.3067, -0.0363, 0.8482]], # [[-0.1414, 1.3067, -0.0363, 0.8482]], # [[ 0.3573, -0.9005, -0.3998, -0.8608]], # [[ 0.3573, -0.9005, -0.3998, -0.8608]]]) mask.unsqueeze(1).repeat_interleave(repeats=2, dim=0) # repeat each seq two multi-head (expected)
6. Flash-Attn V2 mask操作
- 在 flash_attn v1中的,
FlashAttention注意力计算是支持key_padding_mask参数的;同时也提供了封装好的FlashMHA注意力层(包括权重可学习参数)。- !
False代表填充字符,这与上面的MultiheadAttention相反
- !
- 在 flash_attn v2中,flash_attn_func本身是仅用于计算注意力过程,没有mask操作。
|
|
- 在torch v2引入的
F.scaled_dot_product_attention引入了Flash-Attn v2,具体参看上面第三点的介绍。值得注意是,它是支持attn_mask参数的。
attn_mask (optional Tensor) – Attention mask; shape must be broadcastable to the shape of attention weights, which is (N,…,L,S)(N,…,L,S). Two types of masks are supported. A boolean mask where a value of True indicates that the element should take part in attention. A float mask of the same type as query, key, value that is added to the attention score.
如上参数说明有两个注意点
(1)关于shape,不强制要求是(Batch_size*Num_head, Seq_len, Seq_len)。broadcastable也可以;
(2)与Flash-Attn一样,False表示填充/被掩码
|
|
|
|
注意点:
(1)上述仅为单头注意力计算;
(2)F.scaled_dot_product_attention仅提供注意力计算,不能作为完整的注意力层(缺少权重参数)
核心:attn_mask与key_padding_mask参数并没有本质的区别。
补充~
SP1. Performer
- https://arxiv.org/pdf/2009.14794v4 2020 Google Research
- https://github.com/lucidrains/performer-pytorch Pytorch版本实现
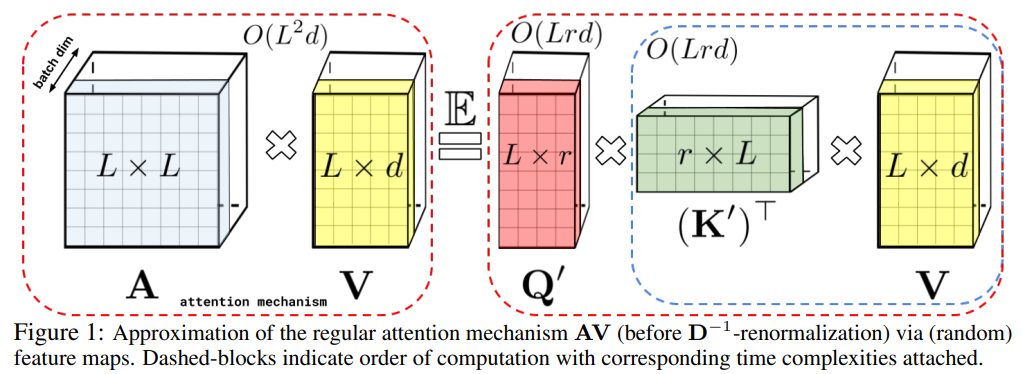
Performer注意力:将复杂度降低到线性,使得它在处理长序列时更加高效;并从理论角度证明是可行的。
对于长度为L的输入序列,嵌入向量长度是d
计算常规Transfomer自注意力时 (下图左栏),其复杂度为O(L2) → Quadratic;
- (1) 注意力矩阵:Q * (K)T = (L, d) * (d, L) = (L, L) → O(L2 * d) → O(L2)
- (2) Softmax计算归一化权重:(L, L) = (L, L) → O(L2)
- (3) 加权和表示:Q * (K)T * V = (L, L) * (L, d) = (L, d) → O(L2 * d) → O(L2)
Performer注意力计算的注意力计算 (下图右栏) 复杂度为O(L) → Linear
- (1) 首先对Q与K进行随机特征映射(Random Feature Mapping)
- Q:(L, d) → Q’ (L, r), K:(L, d) → K’ (L, r)
- (2) 然后计算 (K’)T * V = (r, L) * (L, d) = (r, d) → O(Lrd) → O(L)
- (3) 最后计算 Q’ * (K’)T * V = (L, r) * (r, d) = (L, d) → O(Lrd) → O(L)
计算复杂度时,可忽略常数项、低阶项,以及系数。