1. 优化器optimizer#
1
|
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
|
- AdamW:Adam 的变体,加入了权重衰减来改善正则化效果,在 Transformer 类模型中表现良好。
1
|
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3, weight_decay=1e-2)
|
LAMB 是专为大批量训练设计的优化器,适合大型模型(e.g. BERT)。
2. 学习率调度器#
在深度学习中,学习率调度器 (learning rate scheduler)用于动态调整学习率,以提高模型训练的效率和效果。
在训练大模型时,lr scheduler的设计一般可遵循如下原则:
- Warmup 阶段
- 逐步增加学习率: 从一个较小的值线性或非线性地增加到设定的初始学习率。
- 目的: 稳定训练开始阶段,避免梯度更新过大导致的不稳定。
- 主训练阶段
- 保持或缓慢衰减: 在大部分训练过程中保持学习率不变,或者缓慢衰减。
- 目的: 充分利用初始学习率进行有效的参数更新,快速接近最优解。
- 衰减阶段
- 逐步减小学习率: 使用策略如余弦退火、指数衰减或分段衰减等。
- 目的: 在训练后期细化参数调整,避免振荡,稳定收敛。
下面,主要介绍可以方便实现lr schedule的函数
2.1 torch库#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
import torch
import matplotlib.pyplot as plt
# 一个简单的模型
model = torch.nn.Linear(10, 2)
# 使用 SGD 优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
# 支持的Schedule类型
[s for s in dir(torch.optim.lr_scheduler) if s.endswith("LR")]
# ['ConstantLR',
# 'CosineAnnealingLR',
# 'CyclicLR',
# 'ExponentialLR',
# 'LambdaLR',
# 'LinearLR',
# 'MultiStepLR',
# 'MultiplicativeLR',
# 'OneCycleLR',
# 'PolynomialLR',
# 'SequentialLR',
# 'StepLR']
|
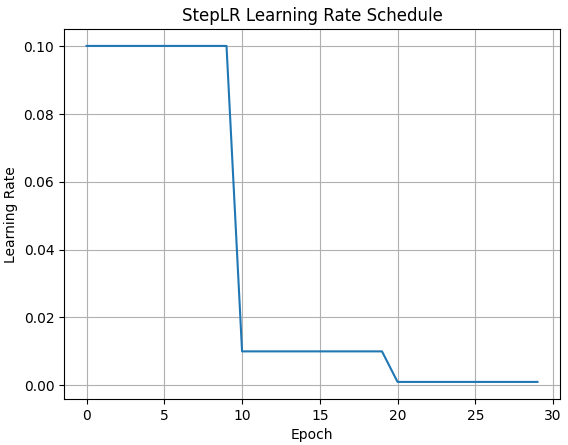
(1) StepLR#
- 每隔一定的步数(step_size),将学习率乘以一个给定的因子(gamma)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
# 创建 StepLR 调度器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)
# 存储学习率的列表
lrs = []
# 模拟训练过程
for epoch in range(30): # 假设训练 30 个 epoch
# 在每个 epoch 开始时记录当前学习率
lrs.append(optimizer.param_groups[0]['lr'])
# 模拟一个 epoch 的训练过程
# train(...)
# 更新学习率
scheduler.step()
# 可视化学习率变化
plt.plot(range(30), lrs)
plt.xlabel('Epoch')
plt.ylabel('Learning Rate')
plt.title('StepLR Learning Rate Schedule')
plt.grid(True)
plt.show()
|
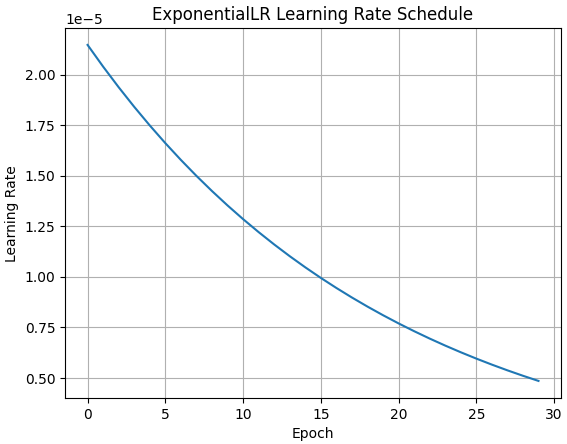
(2) ExponentialLR#
- 每次更新时,将学习率乘以一个固定的指数因子(gamma)。
1
2
|
# 创建 ExponentialLR 调度器
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.95)
|
更多详细示例,见:https://blog.csdn.net/weiman1/article/details/125647517
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
import torch
import transformers
import matplotlib.pyplot as plt
# 一个简单的模型
model = torch.nn.Linear(10, 2)
# 使用 SGD 优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
[s for s in dir(transformers) if s.startswith("get_") & s.endswith("warmup")]
# ['get_constant_schedule_with_warmup',
# 'get_cosine_schedule_with_warmup',
# 'get_cosine_with_hard_restarts_schedule_with_warmup',
# 'get_linear_schedule_with_warmup',
# 'get_polynomial_decay_schedule_with_warmup']
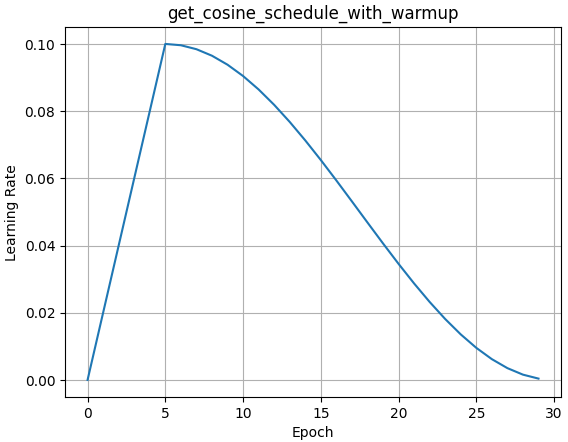
# 创建 get_cosine_schedule_with_warmup 调度器
scheduler = transformers.get_cosine_schedule_with_warmup(
optimizer,
num_warmup_steps=5, #预热的步数
num_training_steps=30, #总训练步数(num_epoch*num_batch)
last_epoch=-1,
)
# 绘图代码同上
|
3. 混合精度训练#
混合精度训练是一种在深度学习中使用不同精度(通常是 FP16 和 FP32)进行计算的方法。Flash-attn使用的就是fp16/bp16。
- 提高性能:使用 FP16(半精度浮点数)可以加速计算;
- 降低内存:FP16 占用的内存是 FP32(单精度浮点数)的一半。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim.lr_scheduler import StepLR
from torch.cuda.amp import autocast, GradScaler
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 简单的神经网络模型
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(28 * 28, 10)
def forward(self, x):
x = x.view(-1, 28 * 28)
return self.fc(x)
# 参数设置
batch_size = 64
learning_rate = 0.01
scheduler_interval = 10
scheduler_factor = 0.1
num_epochs = 5
use_fp16 = True # 是否使用混合精度
# 数据加载
transform = transforms.Compose([transforms.ToTensor()])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# 模型、优化器、调度器、和混合精度缩放器
model = SimpleModel().cuda()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
scheduler = StepLR(optimizer, step_size=scheduler_interval, gamma=scheduler_factor)
scaler = GradScaler(enabled=use_fp16)
# 损失函数
criterion = nn.CrossEntropyLoss()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
for epoch in range(num_epochs):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.cuda(), target.cuda()
optimizer.zero_grad()
# 前向传播
output = model(data)
loss = criterion(output, target)
# 反向传播和优化
loss.backward()
optimizer.step()
# 学习率调度器更新 / batch
# scheduler.step()
# 学习率调度器更新 / epoch
# scheduler.step()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
for epoch in range(num_epochs):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.cuda(), target.cuda()
optimizer.zero_grad()
# 使用 autocast 进行混合精度训练
with autocast(enabled=use_fp16):
output = model(data)
loss = criterion(output, target)
# 使用 GradScaler 进行反向传播
scaler.scale(loss).backward() #损失乘以一个动态缩放因子
scaler.step(optimizer) #更新模型参数
scaler.update() #更新缩放因子
|