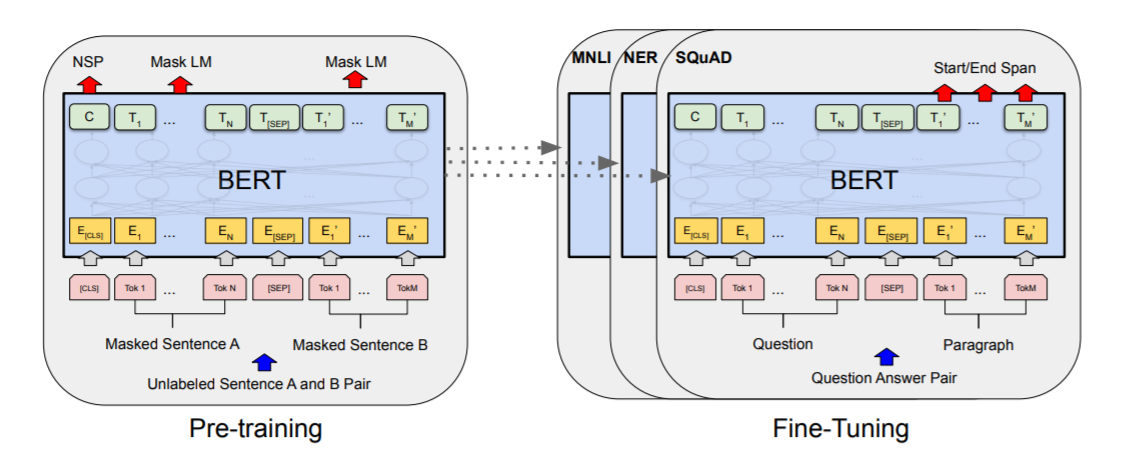
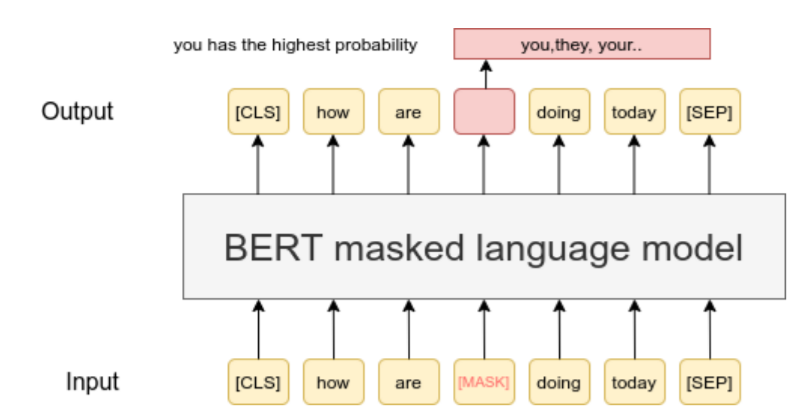
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
devices = d2l.try_all_gpus()
def train_bert(train_iter, net, loss, vocab_size, devices, num_steps):
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
trainer = torch.optim.Adam(net.parameters(), lr=0.01)
step, timer = 0, d2l.Timer()
animator = d2l.Animator(xlabel='step', ylabel='loss',
xlim=[1, num_steps], legend=['mlm', 'nsp'])
# 遮蔽语言模型损失的和,下一句预测任务损失的和,句子对的数量,计数
metric = d2l.Accumulator(4)
num_steps_reached = False
while step < num_steps and not num_steps_reached:
for tokens_X, segments_X, valid_lens_x, pred_positions_X,\
mlm_weights_X, mlm_Y, nsp_y in train_iter:
tokens_X = tokens_X.to(devices[0])
segments_X = segments_X.to(devices[0])
valid_lens_x = valid_lens_x.to(devices[0])
pred_positions_X = pred_positions_X.to(devices[0])
mlm_weights_X = mlm_weights_X.to(devices[0])
mlm_Y, nsp_y = mlm_Y.to(devices[0]), nsp_y.to(devices[0])
trainer.zero_grad()
timer.start()
mlm_l, nsp_l, l = _get_batch_loss_bert(
net, loss, vocab_size, tokens_X, segments_X, valid_lens_x,
pred_positions_X, mlm_weights_X, mlm_Y, nsp_y)
l.backward()
trainer.step()
metric.add(mlm_l, nsp_l, tokens_X.shape[0], 1)
timer.stop()
animator.add(step + 1,
(metric[0] / metric[3], metric[1] / metric[3]))
step += 1
if step == num_steps:
num_steps_reached = True
break
print(f'MLM loss {metric[0] / metric[3]:.3f}, '
f'NSP loss {metric[1] / metric[3]:.3f}')
print(f'{metric[2] / timer.sum():.1f} sentence pairs/sec on '
f'{str(devices)}')
# 结果
train_bert(train_iter, net, loss, len(vocab), devices, 50)
# MLM loss 5.816, NSP loss 0.757
# 6688.3 sentence pairs/sec on [device(type='cuda', index=0), device(type='cuda', index=1)]
|