1. 序列模型
1.1 自回归模型
(1)自回归模型:对于一个包含T个’时间’节点的输入序列,若预测其中的第t个数据,则依赖于该节点前面的观察数据
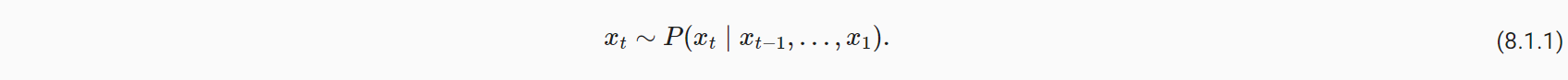
- 基于此,对于整个序列的估计值,可以表示为:
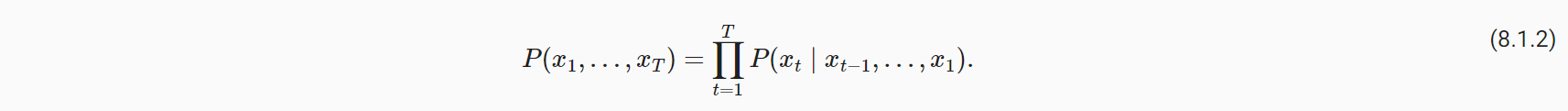
- 然而这对于长序列则计算量过大。我们可以使用该节点前面的τ个样本建模,控制模型参数的数量。
- 如果序列可以按这种方式计算,则认为其满足马尔科夫条件。
- 当τ=1(根据前一个节点推测后一个节点)时,序列估计可以写成如下形式。
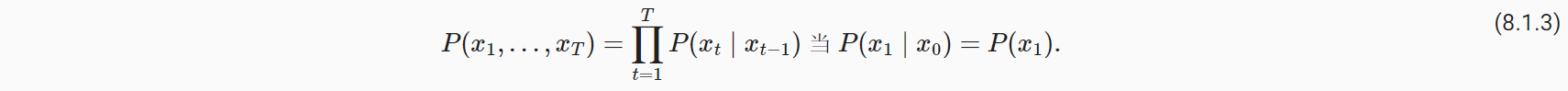
Tips:称为自回归的原因是输入与输出预测同一类型的数据。
(2)隐变量自回归模型 通过一个隐藏(latent):的变量推测Xt的值。而该隐藏变量来自于上一状态的隐变量以及当前Xt-1节点的值。(RNN, Recurrent Neural Network)的思想)

1.2 训练
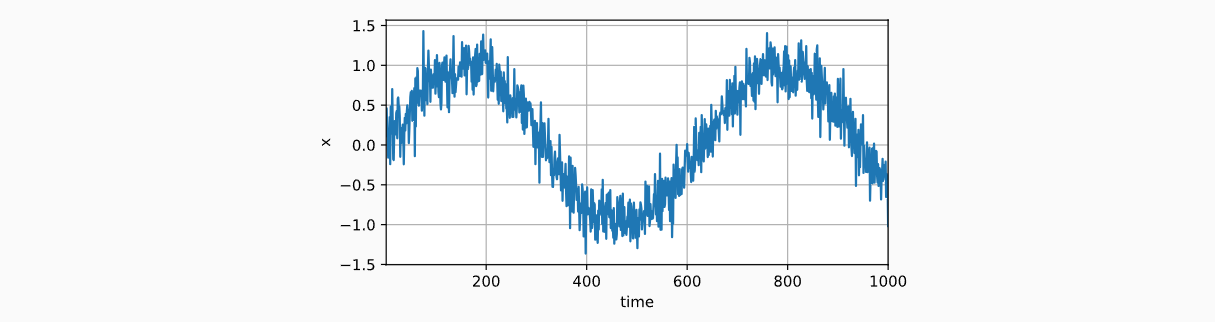
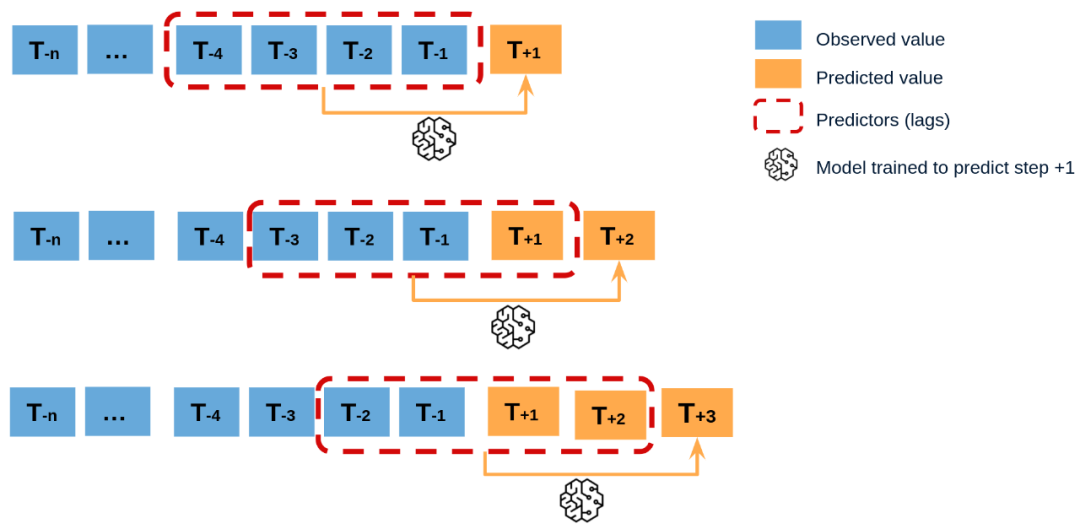
如下将演示如何根据正弦函数的样本点,建立τ=4的自回归模型
- 第一步:模拟正弦函数的数据,x轴从0到1000
|
|
- 第二步:生成特征与标签数据(前4个样本作为输入,第5个样本作为预测)
|
|
- 第三步:建立模型
|
|
- 第四步:训练模型
|
|
1.3 预测
- 预测方式1:特征数据全部来自已知数据
|
|
- 预测方式2:前604个样本来训练集的已知数据。再后面预测时,每次将新预测的样本作为输入预测下一个输出。
|
|
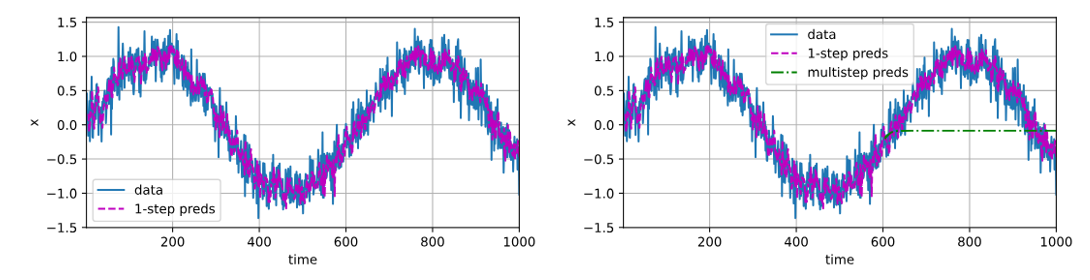
- 如上可以看出:
- 在单步预测(输入均为实际观测数据)时,模型效果不错;
- 而在预测多步(将最近的预测作为下一步输入)时,即更远的预测时,模型效果不尽如人意。
2 文本预处理
一篇文章可以视为一串单词的序列,需要进行必要的预处理操作步骤:
(1)将文本作为字符串进行加载;
(2)将字符串拆分为词元(单词或字符);
(3)建立一个词表,将词元映射到数字索引;
(4)将文本转换为数字索引序列。
2.1 读取数据集
- 示例数据:时光机器(The Time Machine)小说
- 如下操作,按行读取全部小说文本。结果为list,其中每个元素表示一行的文本。
|
|
2.2 词元化
- 词元(token),通常指一个单词或字符
- 如下操作将每一行以词元为单位,拆分为一个list,结果返回一个list of list
|
|
2.3 词表
- 词元的类型是字符串,而模型需要的是数字;
- 词表(Vocabulary):类似于Python中的字典,将输入的词元转换为数字索引;
- 语料库(Corpus):对所有文本中唯一词元的统计结果,按频率降序排。
- 对于低频率出现的词元,可设置一定标准的阈值过滤;
- 对于语料库中不存在,或者已过滤的词元,将被映射到未知词元’<unk>’, 其数字索引记为0
|
|
2.4 整合所有功能
|
|
3. 语言模型和数据集
3.1 自然语言统计
- 单个词元统计(一元语法)
|
|
- 两个连续词元统计(二元语法)
|
|
- 三个连续词元统计(三元语法)
|
|
- 根据下图的频率分布可视化,可以看出:
- 三者均不同程度上遵循齐普夫定律,呈现较为显著的衰减
- 少数高频词占了全部语料库的大多数,大部分可能形式的n元组很少出现
|
|

3.2 读取长序列数据
如前所述,在处理长序列时,通常仅考虑待预测数据前的若干节点的观测数据。
-
batch_size:每个小批量同时处理的子序列样本数目;
-
num_steps:每个子序列中预定义的时间步数。
-
在小批量采样时,由如下两种方式(子序列的时间步数都不重叠)
-
随机偏移量:从一个随机起始点开始截取序列,增加每个epoch迭代的随机性
(1)随机抽样
- 每个批量样本之间的起始时间步数无顺序关系
- e.g. 第一个小批量的第一个序列与第二个小批量的第一个序列无相邻的顺序关系
|
|
- 示例
|
|
(2)顺序分区
- 保证两个相邻的小批量中的子序列在原始序列上也是相邻的。
|
|
- 示例
|
|
Tips:无论上述哪一种方式,生成的序列样本数据都是不重叠的。
整合上述迭代方法
|
|
4. 循环神经网络
- 循环神经网络是具有隐状态的神经网络;
- 隐状态与隐藏层的概念截然不同
- 隐藏层是指在从输入到输出的路径上,隐藏的层;
- 隐状态可以理解为RNN中的记忆单元,它保存了序列中先前时间步的信息,并传递给后续的时间步。
4.1 无隐状态的神经网络
以简单的单隐藏层MLP为例:
- 输入X,隐藏层输出H,隐藏层权重参数Wxh,偏置参数b
- 输出层O,权重参数Whq,偏置参数b
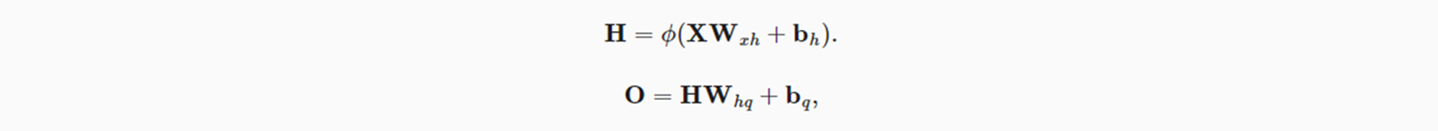
4.2 有隐状态的神经网络
对于一个特定时间步长的序列:
- Xt步的输出(Ot,表示对于Xt+1的预测),取决于当前时间序列的隐状态Ht;
- 而当前的隐状态Ht由当前时间步的输入Xt与前一个时间步的隐状态Ht-1共同计算得出。
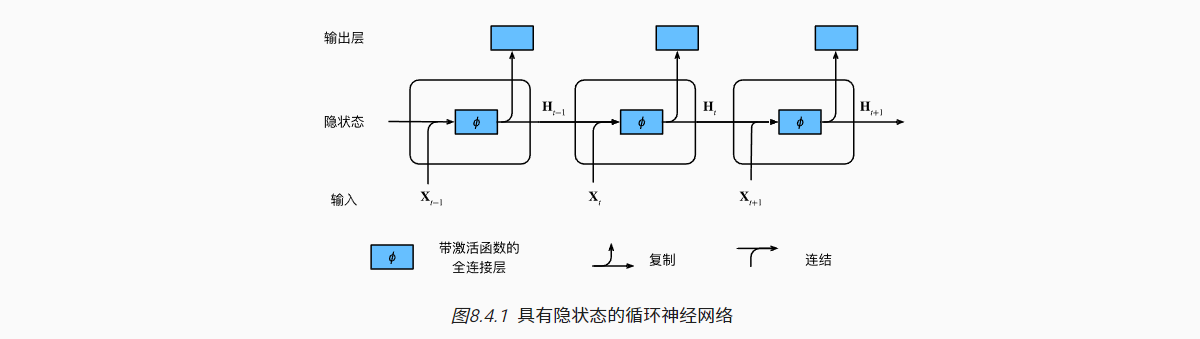
- 对于输入的小批量数据,由n个长度为T的序列样本组成。若样本特征长度为d时,则每次训练输入数据为 Xt:n×d
- 基于Xt的输入,参与Ht计算的权重参数为Wxh;基于Ht-1隐状态,参与Ht计算的权重参数为Whh,此外还有偏置;
- 从Ht隐状态,最终计算Ot的权重参数为Whq,以及偏置。
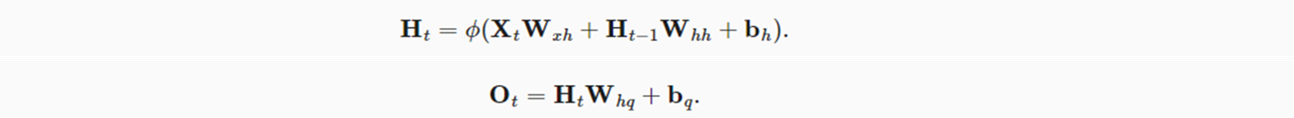
(1)如上可以看出,有隐状态的神经网络从公式上来看,与单隐藏层的神经网络非常类似。只是多了一项Wxh参数的计算过程。
(2)在同一批量的不同时间节点迭代时,仍然是上述这些模型参数。即模型参数的开销不会随着时间步的增加而增加。
- 如下,演示同时对特定一个批量内多个子序列的第i个词元的隐状态计算:
- 输入的批量包含3条子序列,每条子序列中单个词元的特征长度为1;
- 隐状态的神经元个数设置为4。
|
|
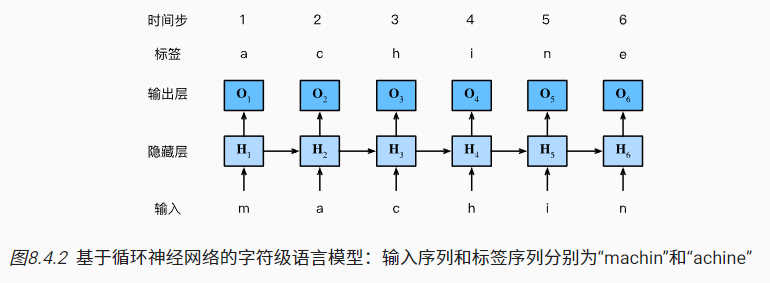
4.3 基于RNN的字符级语言模型
- 在字符级语言模型中,文本词元为字符而不是单词;
- 如下可以理解为小批量大小为1,文本序列为’machine'
4.4 困惑度
- 语言模型大部分情况下可以理解为分类问题,可以利用交叉熵计算模型输入与标签之间的差异;
- 模型性能(损失)可根据一个序列中所有词元(n)的平均交叉熵损失来衡量;
- 实际建模时,自然语言处理的科学家更喜欢使用困惑度(Perplexity)指标。本质上只是对上述进行exp指数运算。
- 该指标可以理解为对下一个词元的实际选择数的调和平均数。
- 困惑度越低,说明模型的预测效果越好。最好的情况为1,即完美地估计了标签词元;
- 如果困惑度为 kk,那么可以理解为模型预测下一个词时的候选词数量大致为 k。
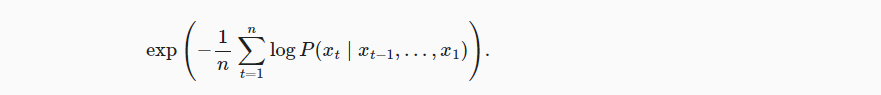
5. RNN的从零实现
从零开始基于RNN实现字符级语言模型
- 读取数据集
- batch_size表示每个批量同时读取/处理多少条子序列
- num_steps表示每条子序列的长度
|
|
5.1 独热编码
- 每个词元经转换后表示为一个数字索引,然后经独热编码表示为特征向量;
- 若词表的唯一词元有N个(
len(vocab)),则词元索引范围是 0~N-1,其特征向量长度为N
|
|
- 特征编码前,小批量输入形状为二维张量(批量大小,时间步数/序列长度)
- 编码后则为3维张量,需要再调整下维度的顺序,方便后续操作。(时间步数/序列长度,批量大小,词表大小/特征长度)
|
|
5.2 初始化模型参数
- RNN模型参数可参考4.2部分介绍,主要分为隐状态参数与输出层参数
|
|
5.3 RNN模型
- 初始化隐状态,形状为(批量大小,隐藏单元数)
|
|
- 定义前向传播函数,返回一轮batch的预测结果(批量大小×序列长度,词表大小),以及更新的隐状态
- 输入inputs为上述5.1所介绍的三维张量
|
|
- 定义模型的类
|
|
- 示例输出
|
|
5.4 预测
- prefix:包含若干词元的初始文本
- num_preds:往后预测多少个词元
- 在预测过程中,首先逐个遍历给定的初始词元,但不做预测,仅用于更新隐状态。
|
|
- 示例
|
|
5.5 梯度剪裁
- 对于长度为T的序列,训练时会执行T次矩阵乘法,来进行反向传播、更新梯度。
- 这对于较长的序列,可能会导致梯度爆炸,模型无法收敛。
- 此时,可以通过梯度剪裁,将参数的梯度的范数设置一个上限θ(不改变方向)。
|
|
5.6 训练
- 在3.2小节中,学习了两种小批量序列样本迭代方法:(1)顺序分区;(2)随机抽样
- 对于顺序分区,相邻两个batch iteration中,对应的第i个子序列的位序也是相邻的。
- 隐状态仅需要在刚开始时初始化一次。在后面的多轮小批量训练时,可以继承。
- 为减少计算量,在处理每个批量数据前,对隐状态参数梯度分离。
- 对于随机抽样,相邻两个batch iteration的序列样本无确定关系(更常用些)
- 隐状态在每个batch iteration时,都需要随机初始化(其权重参数是持续更新的)。
- 如下为训练一个epoch的代码
|
|
- 如下为训练的最终形式
|
|
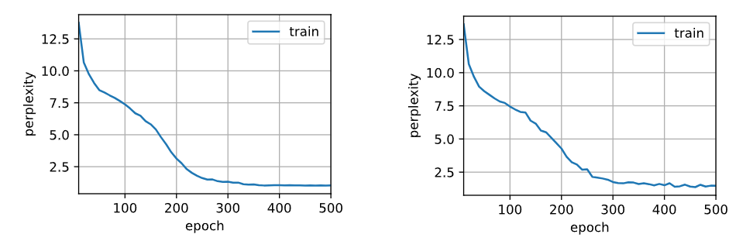
- 实际训练
|
|
6. RNN的简洁实现
- 准备数据
|
|
6.1 定义模型
- 基于torch的
nn.RNN,定义一个具有256个隐藏单元的单隐藏层,其不涉及输出层的计算
|
|
- 初始化隐状态,形状为(隐藏层数,批量大小,隐藏单元数)
|
|
- 模拟计算,更新隐状态
- 如下的Y表示,所有批量的子序列的最后一层的隐状态(一般后面需要再接MLP预测Ot输出)
- state_new表示所有批量的子序列的最后一步的隐状态
|
|
- 定义一个完整的RNNModel类
|
|
6.2 训练与预测
- 训练函数仍参考5.6小节
- 实例化模型
|
|
- 训练模型
|
|