1. 深度卷积神经网络(AlexNet)
1.1 学习表征
LeNet提出后,卷积神经网络并未占据主流,而是往往由其它机器学习方法所超越,如SVM。一个主要的原因是输入数据的特征处理上。
- CNN模型是基于端到端的预测,由模型本身来学习、提取特征。例如直接从图片像素到分类结果的预测;
- SVM等经典机器学习模型则依赖于精细的特征工程,即使用经过人的手工精心设计的特征来建模。
在2012年,AlexNet模型取得了当年ImageNet挑战赛的冠军,标志着深层神经网络相关研究的起点。
在CNN的底层(例如第一层、第二层等)中的每一个通道可以’理解’为对某种模式特征的提取表示,用于更高层的综合学习。

此外,限制神经网络取得良好性能的因素还包括数据与硬件两方面——
- 数据:深度模型需要大量的有标签数据才能显著优于基于凸优化的传统方法(如线性方法和核方法)
- 2009年,由斯坦福教授李飞飞小组发布了ImageNet数据集,并发起ImageNet挑战赛:要求研究人员从100万个样本中训练模型,以区分1000个不同类别的对象。
- 硬件:深度学习模型对计算资源要求很高,需要数百次迭代训练;每次迭代有需要许多线性代数层传递数据。
- 相比于CPU,GPU用于大量的计算核心,方便并行运算;此外也提供更高的浮点运算性能(FLOPS),并配备有高带宽的显存(VRAM)等优势。
1.2 AlexNet
本书在这里提供的是一个稍微精简版本的AlexNet
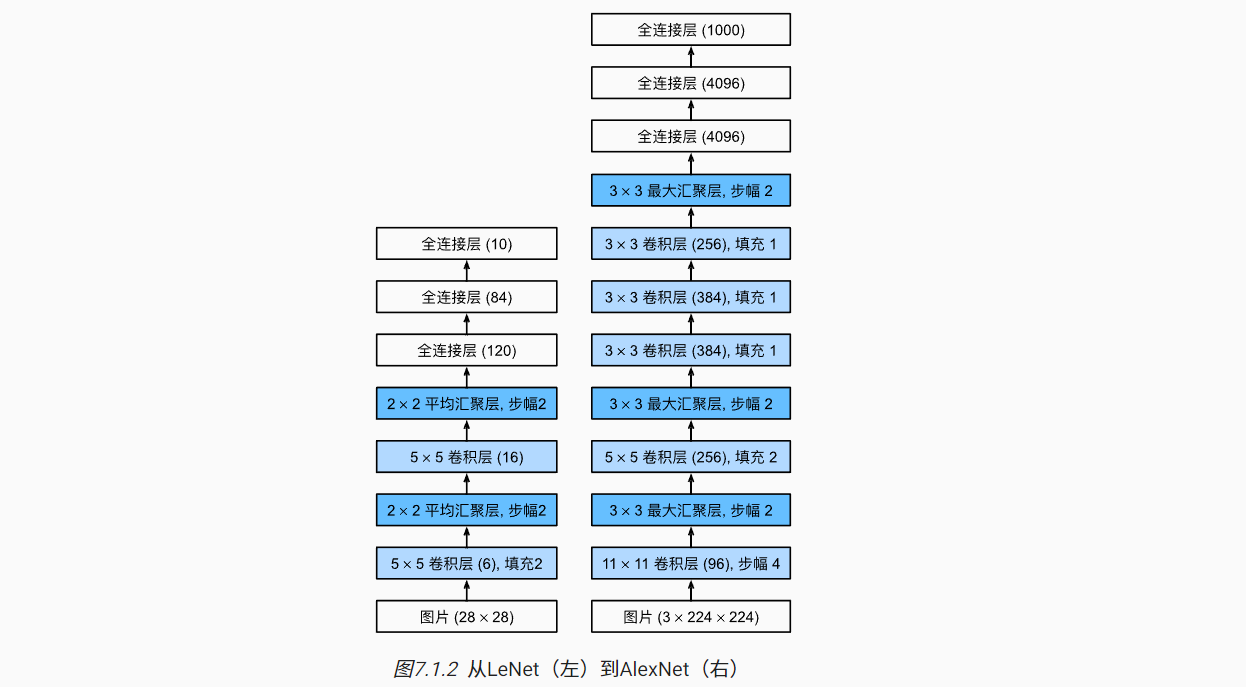
AlexNet与LeNet架构非常相似,在以下方面进行了提升:
- 模型设计:由8层组成,包括5个卷积层、3个全连接层
- 考虑ImageNet图像宽高显著多于MNIST,第1个卷积层的卷积核窗口为11×11,第二个为5×5,往后都是3×3;
- 卷积输出通道数也是LeNet的10倍以上;
- 在第1、第2、第5层卷积层后加入最大汇聚层;
- 两个全连接隐藏层有4096个输出,用于接近1GB的模型参数;
- 激活函数:使用ReLU激活函数相比于Sigmoid计算更加简单,且更适应多种参数初始化方法。
- 容量控制:使用Dropout暂退法控制了全连接层的模型复杂度。
- 如下的模型架构是为Fashion-MNIST数据集修改后的设计,主要体现在第一层卷积层的输入通道数为1。
|
|
- 以一个高度和宽度都为224的单通道输入数据为例
|
|

1.3 读取数据集
- 为了将Fashion-MNIST数据用于AlexNet模型框架,需要将像素分辨率重新设置为224×224
|
|
1.4 训练AlexNet
|
|
2 使用块的网络(VGG)
- AlexNet虽然证明深层网络有效,但未能提供通用的模板指导后续的设计;
- VGG由牛津大学的视觉几何组于2013年提出,可以简洁地实现更深更窄的网络,在2014年ImageNet中取得优异的表现。
2.1 VGG块
VGG块提出了一种经典的卷积神经网络的组成架构,包括如下:
- 多个连续的卷积层
- 较小的3×3卷积核;
- 带填充以保持输出分辨率不变;
- 自定义输出通道。
- ReLU激活函数;
- 步幅为2的2×2最大汇聚层,使得输出高宽减半
代码实现如下,可调整参数包括:
- num_convs 块包含多少个卷积层;
- in_channels 输入通道数
- out_channels 输出通道数
|
|
2.2 VGG网络
参考AlexNet,VGG同样可以分为两部分:
- 第一部分由多个VGG块组成的卷积层部分;
- 第二部分由3个的全连接层组成。
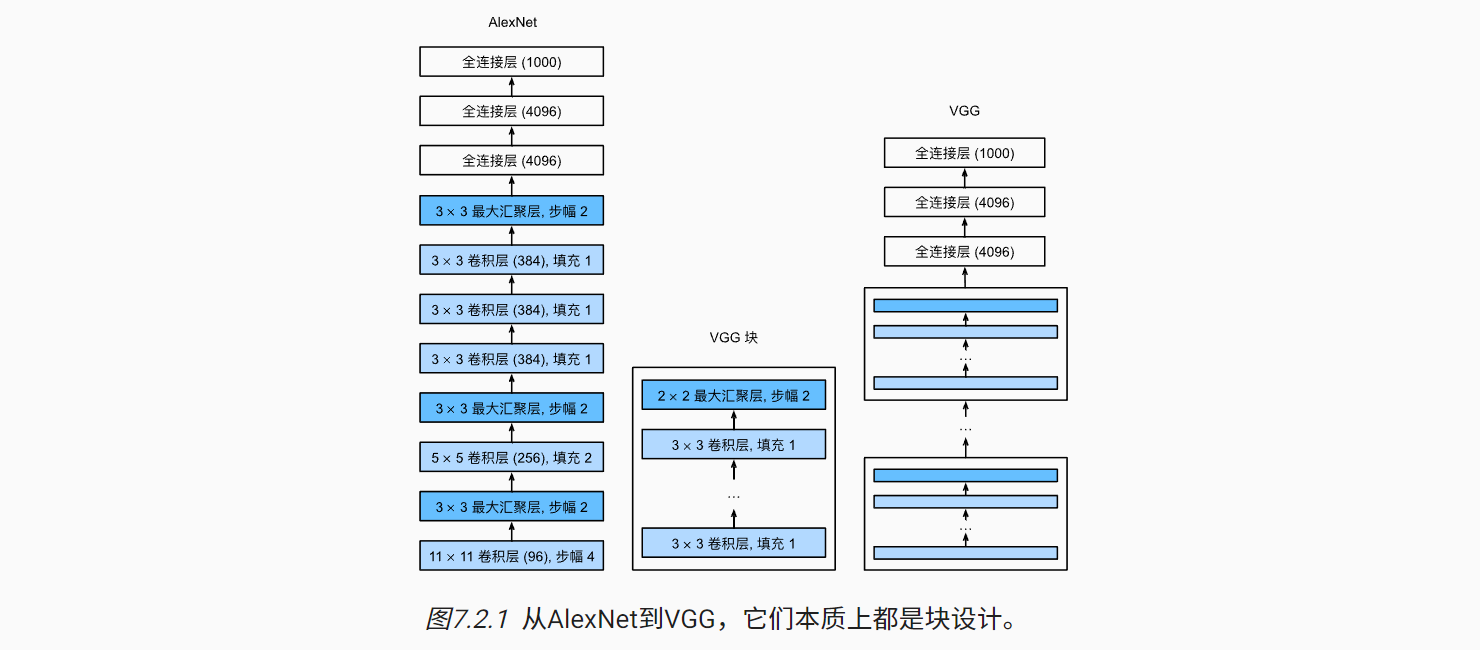
原始VGG网络包含如下5个VGG块,共有5个卷积层;结合三个全连接层,因此又称为VGG-11。
- 第一个块:1个卷积层,64个输出通道;
- 第二个块:1个卷积层,128个输出通道;
- 第三个块:2个卷积层,256个输出通道;
- 第四个块:2个卷积层,512个输出通道;
- 第五个块:2个卷积层,512个输出通道;
|
|
由于每个块的最后一层都是最大汇聚层,使得输出减半;同时增加输出通道数。这是经典的CNN设计思路。
|
|

2.3 训练模型
- 由于VGG-11比AlexNet计算量更大,因此这里构建了一个通道数较少的网络
|
|
3. 网络中的网络(NiN)
- 在前述介绍的网络组成中,在最后通常会加入全连接层,会导致引入大量的模型参数;
- 1×1卷积核可以起到混合通道的作用,有点类似MLP的全连接层;
- NiN网络在AlexNet的基础之上,使用了1×1卷积核,取代了上述全连接层部分的作用。
3.1 NiN块
NiN块提出了一种特殊的组成架构,包括如下:
- 第一层为用户自定义的卷积层,以及ReLU激活函数;
- 第二、三层为1×1卷积核的卷积层,输出通道数不变,同样分别加入ReLU激活函数;
使用1×1卷积核时,相当于对同一位置,不同通道的元素进行全连接层

代码实现如下:
|
|
3.2 NiN模型
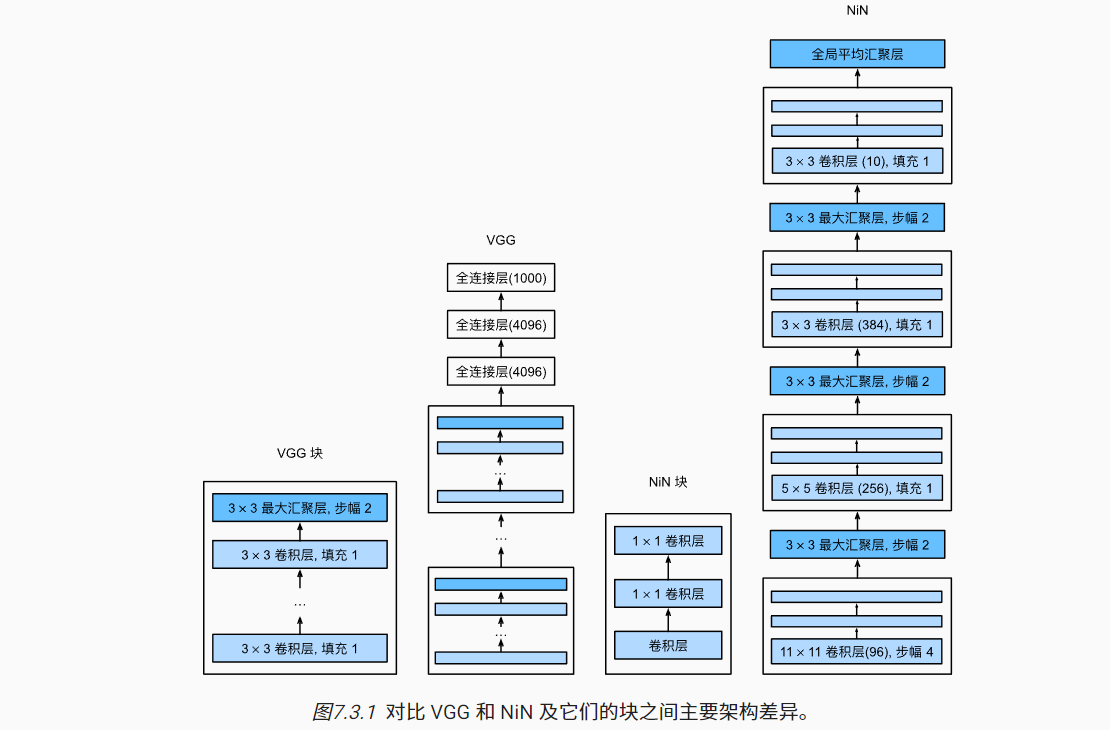
- 由4个NiN块组成,每个NiN块中的卷积核窗口参考AlexNet设置为11×11,5×5,3×3,3×3
- 前3个NiN块后接一个最大池化层;
- 最后一个NiN块的输出通道数等于类别数,且后面接一个全局平均池化层,输出为1×1
|
|

3.3 训练模型
|
|
4. 含并行连接的网络(GoogLeNet)
- 基于NiN中串联网络的思想,GoogLeNet在2014年ImageNet图像识别挑战赛的取得佳绩;
4.1 Inception块
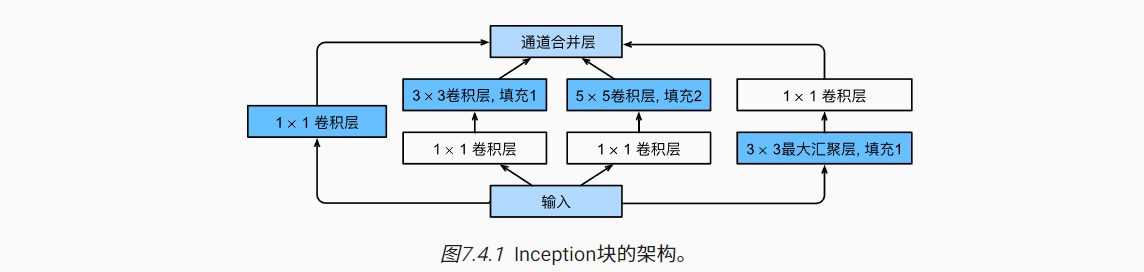
如下图,Inception块由4条并行的路径组成,每个路径仅改变通道数,不改变高宽。
- 第一条:1×1卷积
- 第二条:1×1卷积,加上3×3卷积(填充1)
- 第三条:1×1卷积,加上5×5卷积(填充2)
- 第四条:3×3最大汇聚(填充1),加上1×1卷积
如下是定义Inception块的代码,其中可调参数均是输入以及每条路径中的通道数。
- in_channels 输入通道数;
- c1 第一条路径的输出通道数;
- c2 第二条路径每个卷积层的输出通道数;
- c3 第三条路径每个卷积层的输出通道数;
- c4 第四条路径每个卷积层的输出通道数;
|
|
4.2 GoogLeNet模型
如下示意图,GoogLeNet模型共有5个部分组成(从下到上):
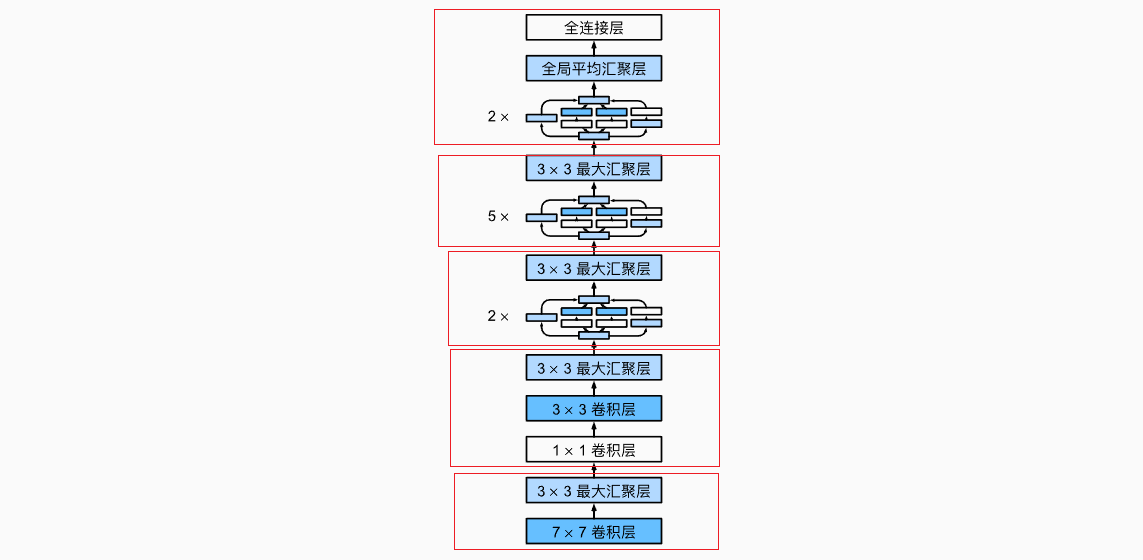
- 第一部分:类似于AlexNet,一个卷积层加上一个最大汇聚层;
|
|
- 第二部分:两个卷积层加上一个最大汇聚层
|
|
- 第三部分:2个Inception块,加上最大汇聚层
- e.g. 第一个卷积层:输入通道=192,输出通道=64+128+32+32=256
|
|
- 第四部分:5个Inception块,加上最大汇聚层
- e.g. 第一个卷积层:输入通道=480,输出通道=192+208+48+64=512
|
|
- 第五部分:2个Inception块,加上全局平均汇聚层以及全连接层
- e.g. 最后一层卷积层:输入通道=832,输出通道=384+384+128+128=1024
- 全局平均汇聚层以及Flatten将输出变为1024的特征向量,后面再根据类别数接一个全连接层
|
|
- 查看模型架构(仍是高宽变小,通道数变多的思想)
|
|

4.3 训练模型
|
|
5. 批量规范化
- 加速深层神经网络的收敛
5.1 训练深层网络
-
批量规范化(Batch Normalization, BN)用于对特定神经网络层中,每次训练迭代的小批量输入数据进行’归一化’处理。
-
这使得不同层之间的参数量级得到统一,防止模型参数的更新是为了补偿不同层之间的数据差异,从而针对性的对预测问题本身进行学习,加速模型收敛。
-
具体实现其实也并不复杂:
(1)首先对一个小批量B,计算其(feature)均值与方差
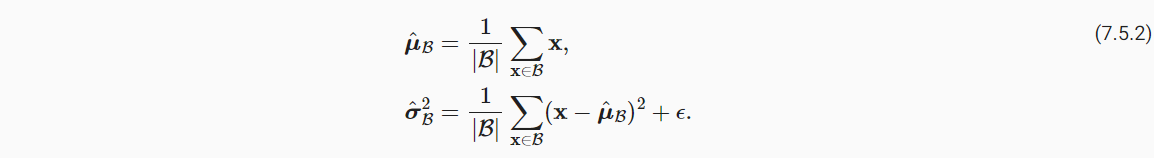
(2)然后,进行均值为0,方差为1的归一化处理后,进一步进行拉伸与偏移。γ可以变换方差,β可以变换均值,均属于可学习的参数,从而拟合最适合的规范化分布。
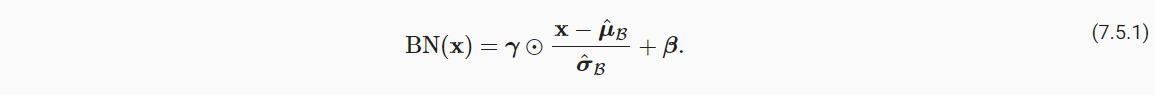
一种角度的解释是BN操作中会引入一定的噪声,控制了模型复杂度。因为随机抽样的小批量分布不能代表总体情况。
5.2 批量规范化层
- 对于全连接层:
- BN操作位于全连接层与激活函数之间;
- 对于[小批量数,特征数]的输入数据,会对每一列特征进行BN操作。即每个特征学习的γ与β都是不同的;
- 对于卷积层
- BN操作位于卷积层与激活函数之间;
- 对于多通道输出,会将每个通道作为一个特征,即计算小批量样本对于特定通道的,所有元素的均值与方差。
- 此外,BN操作在预测过程是估算特征在整个训练数据集的均值与方差,再进行规范化。
5.3 从零实现
- 首先定义一个函数,进行BN操作
|
|
- 然后定义一个BatchNorm层
|
|
5.4 使用批量规范化层的LeNet
- 定义模型
|
|
- 训练模型
|
|
- 查看模型BN层的γ与β参数
|
|
6. 残差网络(ResNet)
- 残差网络主要由何凯明等人提出,在2015年ImageNet挑战赛中取得了冠军。
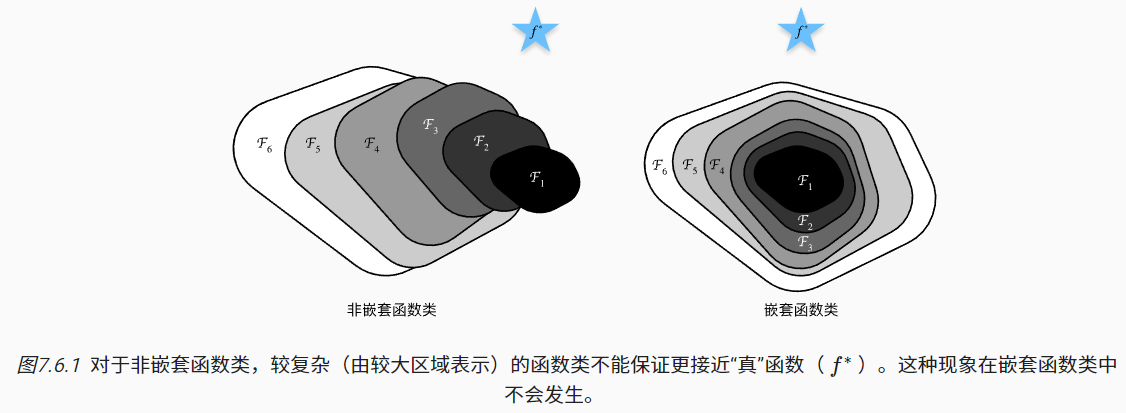
6.1 函数类
(1)非嵌套函数类
- 新模型 = 新添加的层 ← 原模型
- 在先前学习的深度神经网络中,每个神经网络层/块基本独立非嵌套关系,即前者的输出直接作为后者的输入。对于复杂的模型架构,有时新添加的层并不能使模型接近最优解,甚至可能更糟;
(2)嵌套函数类
- 新模型 = 新添加的层 + 原模型
- 如果新添加的层效果不明显,新模型仍然有机会基于原模型更新梯度。即新模型可能得出更优的解来拟合数据集(至少不会变差)。
6.2 残差块
- 如下左图,为一个正常的神经网络架构,若输出为f(x)。
- 由输入x,经神经网络层映射,得到输出f(x)
- 如下右图,为一个残差块架构,若输出为f(x)。
- 由输入x,经神经网络层与原数据共同组成f(x)。
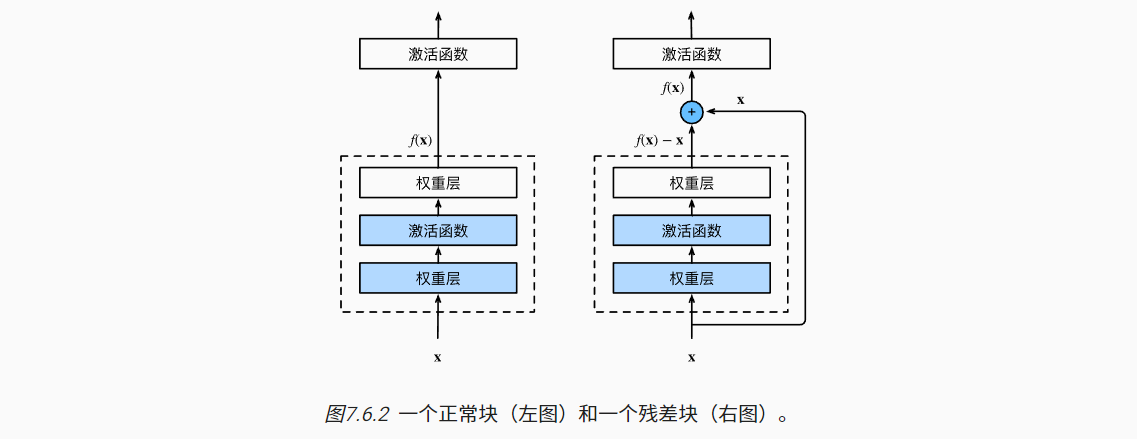
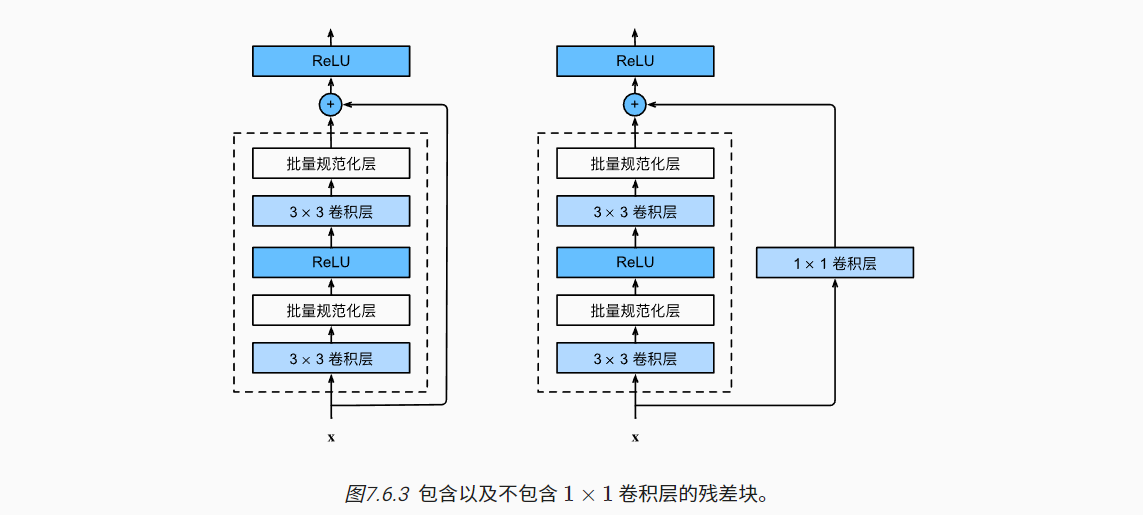
- ResNet网络中残差块共有两种,区别在于原模型数据的输入:
- 一种是原模型的x直接输入
- 另一种是原模型的x经1×1卷积层后再输入
|
|
- 查看示例输出
|
|
6.3 ResNet模型
ResNet模型由如下部分组成
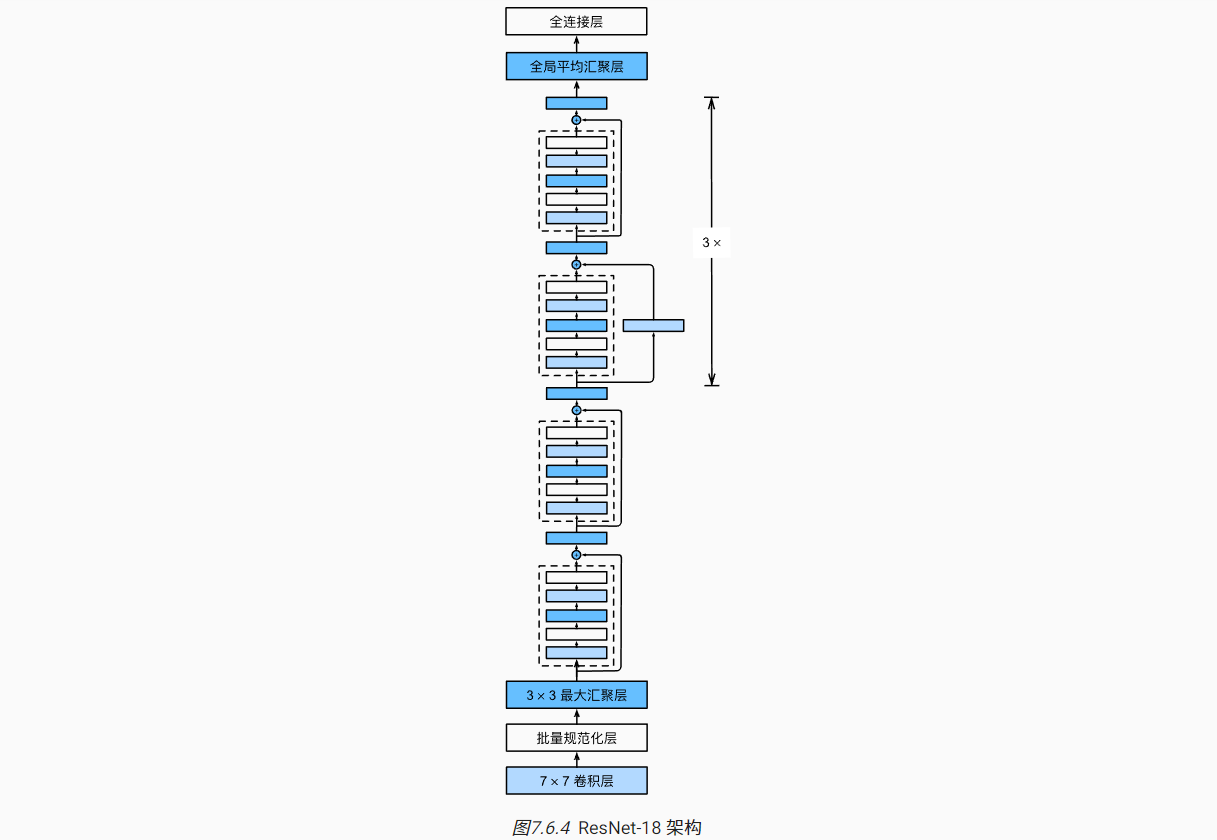
- 第1部分:卷积层+BN+最大汇聚层,64通道输出,高宽降低四倍
|
|
- 第2~5部分由4个block组成,每个block包含两个2残差块
- 除了第1个Block以外的第1个残差块都需要将高宽减半,通道数加倍
|
|
- 最后的第6部分连接全局平均汇聚层以及全连接输出层
|
|
4个Block包含共包含8个残差块,共16个卷积层,加上第一个卷积层以及最后一个全连接层,共有18层,因此又称为ResNet-18。
- 查看示例形状输出
|
|

6.4 训练模型
|
|
7. 稠密连接网络(DenseNet)
- DenseNet相当于是ResNet的逻辑扩展。
7.1 从ResNet到DenseNet
- ResNet和DenseNet的关键区别在于,DenseNet输出是连接(用图中的[,]表示)而不是如ResNet的简单相加。
- 稠密网络主要由2部分构成:稠密块(dense block)和过渡层(transition layer)。 前者定义如何连接输入和输出,而后者则控制通道数量,使其不会太复杂。

7.2 稠密块
- 基本的“批量规范化、激活和卷积”架构
|
|
- 一个稠密块由多个卷积块组成,每个卷积块使用相同数量的输出通道;
- 在前向传播中,我们将每个卷积块的输入和输出在通道维上连结。
|
|
- 示例展示:第一层输入通道数为3,第二层输入通道数是10+3,第二次输出通道数是10 + 10 + 3
|
|
7.3 过渡层
- 上述稠密层会导致通道数的不断累加、增多
- 过渡层用来控制模型复杂度,通过1×1卷积层来减小通道数,并使用步幅为2的平均汇聚层减半高和宽。
|
|
7.4 DenseNet模型
架构基本类似ResNet。
- 第一部分由单卷积层和最大汇聚层组成
|
|
- 后面再接4个稠密快,每个块由4个卷积层组成
|
|
- 最后接上全局汇聚层和全连接层来输出结果。
|
|
7.5 训练模型
|
|