1. 线性回归
1.1 线性回归的基本元素
- 线性模型:目标(y)可以表示为输入特征的加权和,参数包括权重向量w和偏置b
- 损失函数:表示目标的实际值与预测值之间的差距;一般数值越小,损失越小。回归问题常用平方误差函数,如下公式。
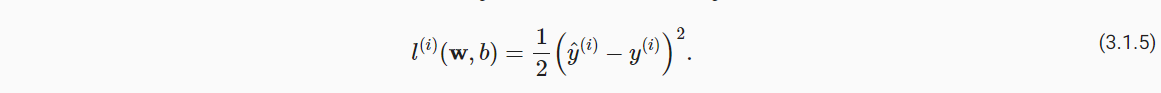
-
解析解:可以直接计算梯度为0时的参数值。仅对于线性回归类简单问题存在,大部分深度学习问题不存在。
-
随机梯度下降:不断在损失函数递减的方向上更新参数来降低误差。
在实际应用中,常采用小批量随机梯度下降。
- 即随机抽取少量样本(B),计算该批量的损失均值关于模型参数的导数;
- 然后,将梯度乘以一个预先确定的正数(η,学习率),并从当前参数的值中减去(梯度负方向上更新参数)。
这里的B,η为超参数,需要人为指定,不会在训练中更新。模型调参即选择超参数的过程。
-
用模型预测:基于训练的模型,预测新的样本的结果。
1.2 向量化加速
- 向量化运算可以显著提高运算时间
|
|
1.3 正态分布与平方损失
- 假设线性回归(的噪声)遵循正态分布,我们可以计算通过给定的x样本观测到特定y标签的似然;
- 根据极大似然估计法,参数w与b的最优值是使得整个数据集的似然最大的值;
- 由于损失问题通常是最小化计算,因此需要对计算公式取-log转换;
- 最后可证明在高斯噪声的假设下,最小化均方误差等价于对线性模型的极大似然估计。

1.4 从线性回归到深度网络
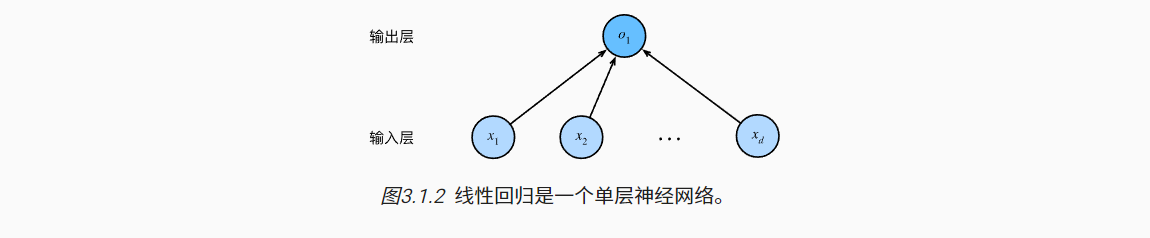
- 线性回归可以理解为一个单层神经网络;其中每个输入都与每个输出(线性回归只有一个输出)连接。这种变换又称为全连接层,或者稠密层。
- 线性回归其实早于神经科学。
2. 线性回归从零实现
2.1 生成数据集
- 生成一个模拟数据集,两个输入特征,一个输出:y = 2x - 3.4z
|
|
2.2 小批量读取数据集
- 小批量数据迭代生成
|
|
2.3 初始化参数
- 随机初始化模型的参数
|
|
2.4 定义模型
- y = Xw + b
|
|
2.5 定义损失函数
- 对于回归问题,常采用平方误差损失函数;
|
|
2.6 定义优化算法
- 将模型参数按照梯度的反方向更新;更新大小由学习率η决定。
- 由于是小批量样本的梯度,需要取均值;使其更新步长不受批量的影响
|
|
2.7 训练
- 每个epoch扫一次全部的样本,涉及多个小批量(取决于Batch大小);
- (1)计算小批量的损失
- (2)计算参数的梯度
- (3)更新参数
|
|
3. 线性回归的简洁实现
在Pytorch中,对于数据迭代器、损失函数、优化器和神经网络都有简单、高效的实现方式
3.1 生成数据集
- 操作步骤同前
|
|
3.2 读取数据集
- 调用Pytorch的数据迭代器
|
|
3.3 定义模型
- Sequential类可以将多个神经网络层串联在一起;
- Linear类用于定义全连接层,其中第一个参数指定输入特征形状;第二个参数指定输出特征形状。
|
|
3.4 初始化模型参数
|
|
3.5 定义损失函数
|
|
3.6 定义优化算法
- SGD小批量随机梯度下降算法,交代模型参数以及学习率
|
|
3.7 训练
- 逻辑与2.7类似
- 迭代小批量样本
- 计算损失
- 计算梯度
- 参数更新
|
|
4. softmax回归
4.1 分类问题
- 独热编码用于表示分类数据;
- 其本质为一个向量,元素分量与类别数一样多;
- 对于某个具体样本,真实类别对应的分量为1,其它分量为0。
4.2 网络架构
- 具有多个输出的单层神经网络模型,以分别估计每个类别的概率;
- 基于全连接层的特性,所有输入特征都与每个输出建立关系;

4.3 全连接层的参数开销
- 若具有d个(特征)输入,q的输出(类别)的全连接层,则参数开销为O(dq)
4.4 softmax运算
- 将模型输出结果视为概率的前提是(1)非负,(2)和为1;
- Softmax操作可以将输出进行转换,满足上述条件。(1)首先将输出结果求幂(2)每个求幂的结果除以结果的总和;
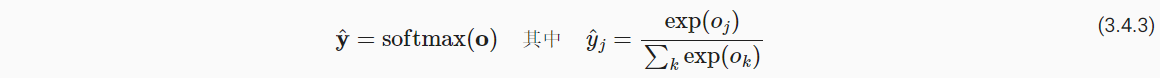
虽然softmax是一个非线性函数,但softmax回归的输出还是由输出特征的全连接层得到的,因此softmax回归是线性模型
4.5 小批量样本的向量化
对于具有n个样本,特征维度为d,类别数为q的小批量数据:
- 特征矩阵X: n × d
- 权重W:d × q
- 偏置b:1 × q
- 输出结果O:n × q
4.6 损失函数
- 多分类问题常使用交叉熵作为损失函数,其只关心(最大化)对于正确类别预测的预测概率;

此外,也可从信息论的角度理解交叉熵损失,详见教材3.4.7小结
5 图像分类数据集
- Fashion-MNIST数据集:10个类别图像组成;6000个训练样本,1000个测试样本
|
|
5.1 读取数据集
- 下载到本地上一级的data目录下
|
|
5.2 读取小批量
- 参考3.2,使用Pytorch的Dataloader类
|
|
5.3 整合所有组件
- 合并上述操作于一个函数
- resize参数表示调整,修改图片的形状
|
|
6 softmax回归的从零开始实现
- 设置数据迭代器的批量大小为256
|
|
6.1 初始化模型参数
- 这里将每个样本视为长度为784的向量
|
|
6.2 定义Softmax操作
- (1)非负;(2)和为1
|
|
6.3 定义模型
- 先计算原始计算结果;在进行softmax转换
|
|
6.4 定义损失函数
- 参考4.6步骤,交叉熵损失函数主要计算模型对于真实标签类别的负对数似然
|
|
6.5 分类精度
- 通常取预测概率最高的类别作为预测结果;
- 分类精度是正确预测数与预测总数之比。
|
|
- 对于数据迭代器,评估其在全部数据集的精度
|
|
6.6 训练
- 定义一个函数训练一轮
|
|
- 定义一个训练函数,会运行多个epoch。每个epoch训练完,会评估在test测试数据的效果
|
|
- 优化函数
|
|
- 开始训练
|
|
7. softmax回归的简洁实现
- 设置数据迭代器的批量大小为256
|
|
7.1 初始化模型参数
|
|
7.2 损失函数
|
|
7.3 优化算法
|
|
7.4 训练
|
|