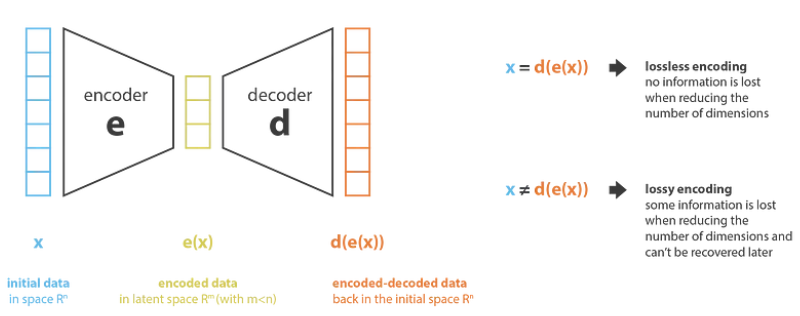
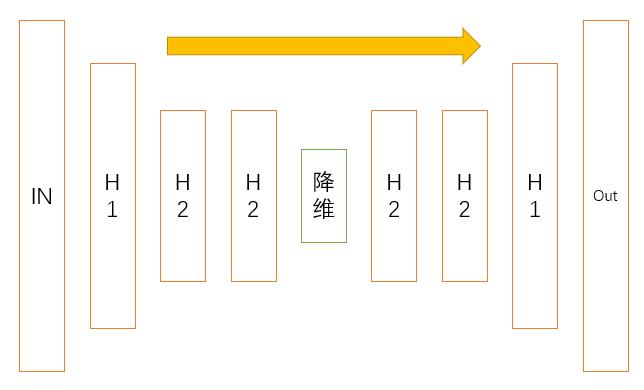
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
|
class Autoencoder(nn.Module):
def __init__(self,D_in,H=50,H2=12,latent_dim=3):
#Encoder
super(Autoencoder,self).__init__()
self.linear1=nn.Linear(D_in,H)
self.lin_bn1 = nn.BatchNorm1d(num_features=H)
self.linear2=nn.Linear(H,H2)
self.lin_bn2 = nn.BatchNorm1d(num_features=H2)
self.linear3=nn.Linear(H2,H2)
self.lin_bn3 = nn.BatchNorm1d(num_features=H2)
# Latent vectors mu and sigma
self.fc1 = nn.Linear(H2, latent_dim)
self.bn1 = nn.BatchNorm1d(num_features=latent_dim)
self.fc21 = nn.Linear(latent_dim, latent_dim)
self.fc22 = nn.Linear(latent_dim, latent_dim)
# Sampling vector
self.fc3 = nn.Linear(latent_dim, latent_dim)
self.fc_bn3 = nn.BatchNorm1d(latent_dim)
self.fc4 = nn.Linear(latent_dim, H2)
self.fc_bn4 = nn.BatchNorm1d(H2)
# Decoder
self.linear4=nn.Linear(H2,H2)
self.lin_bn4 = nn.BatchNorm1d(num_features=H2)
self.linear5=nn.Linear(H2,H)
self.lin_bn5 = nn.BatchNorm1d(num_features=H)
self.linear6=nn.Linear(H,D_in)
self.lin_bn6 = nn.BatchNorm1d(num_features=D_in)
self.relu = nn.ReLU()
def encode(self, x):
lin1 = self.relu(self.lin_bn1(self.linear1(x)))
lin2 = self.relu(self.lin_bn2(self.linear2(lin1)))
lin3 = self.relu(self.lin_bn3(self.linear3(lin2)))
fc1 = F.relu(self.bn1(self.fc1(lin3)))
r1 = self.fc21(fc1)
r2 = self.fc22(fc1)
return r1, r2
def reparameterize(self, mu, logvar):
if self.training:
std = logvar.mul(0.5).exp_()
eps = Variable(std.data.new(std.size()).normal_())
return eps.mul(std).add_(mu)
else:
return mu
def decode(self, z):
fc3 = self.relu(self.fc_bn3(self.fc3(z)))
fc4 = self.relu(self.fc_bn4(self.fc4(fc3)))
lin4 = self.relu(self.lin_bn4(self.linear4(fc4)))
lin5 = self.relu(self.lin_bn5(self.linear5(lin4)))
return self.lin_bn6(self.linear6(lin5))
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparameterize(mu, logvar)
# self.decode(z) ist später recon_batch, mu ist mu und logvar ist logvar
return self.decode(z), mu, logvar
class customLoss(nn.Module):
def __init__(self):
super(customLoss, self).__init__()
self.mse_loss = nn.MSELoss(reduction="sum")
# x_recon ist der im forward im Model erstellte recon_batch, x ist der originale x Batch, mu ist mu und logvar ist logvar
def forward(self, x_recon, x, mu, logvar):
loss_MSE = self.mse_loss(x_recon, x)
loss_KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return loss_MSE + loss_KLD
def weights_init_uniform_rule(m):
classname = m.__class__.__name__
# for every Linear layer in a model..
if classname.find('Linear') != -1:
# get the number of the inputs
n = m.in_features
y = 1.0/np.sqrt(n)
m.weight.data.uniform_(-y, y)
m.bias.data.fill_(0)
|