1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
|
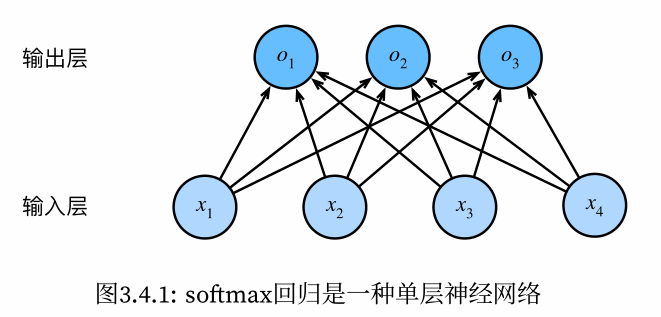
## (1) 示例数据
def load_data_fashion_minist(batch_size):
trans = transforms.ToTensor()
mnist_train = torchvision.datasets.FashionMNIST(
root="./data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(
root="./data", train=False, transform=trans, download=True)
train_iter = data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True)
test_iter = data.DataLoader(mnist_train, batch_size=batch_size, shuffle=False)
return train_iter, test_iter
# batch_size = 256
# train_iter, test_iter = load_data_fashion_minist(batch_size)
# X, y = next(iter(train_iter))
# X.shape
# # torch.Size([256, 1, 28, 28])
## (2) 定义模型
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 10))
# len(net)
# # 2
# net[1].weight
# net[1].bias
# y_hat = net(X)
# y_hat.shape
# # torch.Size([256, 10])
## (3) 定义损失函数
loss = nn.CrossEntropyLoss(reduction='none')
# loss(y_hat, y).shape
# # torch.Size([256])
# 计算1个batch的分类正确数
def accuracy(y_hat, y):
y_hat_class = y_hat.argmax(1)
# 样本类别预测与否(True/False)
cmp = y_hat_class.type(y.dtype) == y
return cmp.sum().item()
# accuracy(y_hat, y)
# # 13
# 定义一个累加值计数器:用以累计1轮epoch所有batch的分类精度
class Accumulator:
def __init__(self, n):
self.data = [0.0]*n
# [0, 0]
def add(self, *args):
# [0, 0] + [1, 2] = [1, 2]
self.data = [a + b for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0]*len(self.data)
def __getitem__(self, idx):
return self.data[idx]
# 计算测试集的分类精度
def evaluate_accuracy(net, data_iter):
metric = Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
metric.add(accuracy(net(X), y), len(y))
Acc_avg = metric[0]/metric[1]
return Acc_avg
# evaluate_accuracy(net, test_iter)
# # 0.0515
## (4) 定义优化算法
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 10))
optimizer = torch.optim.SGD(net.parameters(), lr = 0.1)
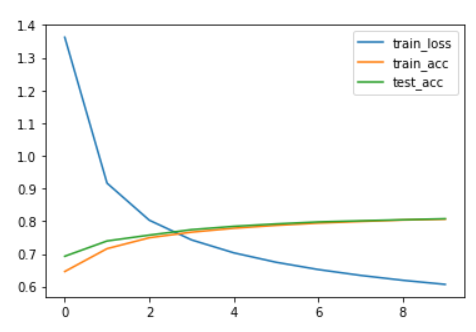
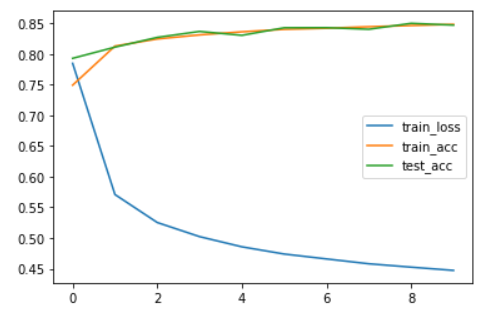
## (5) 训练模型
batch_size=256
train_iter, test_iter = load_data_fashion_minist(batch_size)
epoch_metric = []
num_epochs = 10
for epoch in range(num_epochs):
train_metric = Accumulator(3)
net.train()
for X, y in train_iter:
y_hat = net(X)
l = loss(y_hat, y)
optimizer.zero_grad()
l.mean().backward()
optimizer.step()
train_metric.add(l.sum().item(), accuracy(y_hat, y), len(y))
acc_avg = train_metric[1]/train_metric[2]
loss_avg = train_metric[0]/train_metric[2]
net.eval()
test_acc_avg = evaluate_accuracy(net, test_iter)
epoch_metric.append([loss_avg, acc_avg, test_acc_avg])
print(f'epoch {epoch + 1},train loss {loss_avg:.3f} | train acc {acc_avg:.3f} | test acc {test_acc_avg:.3f}')
import pandas as pd
epoch_metric_df = pd.DataFrame(epoch_metric, columns=["train_loss","train_acc","test_acc"])
epoch_metric_df.plot.line()
|