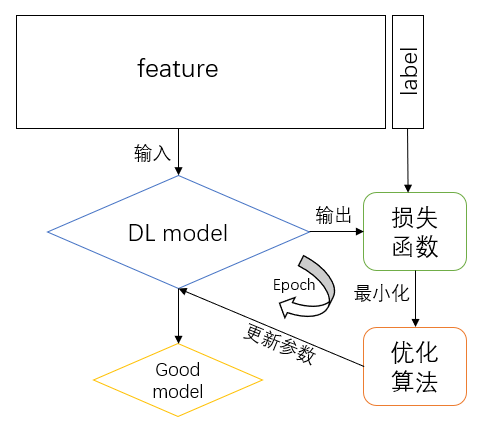
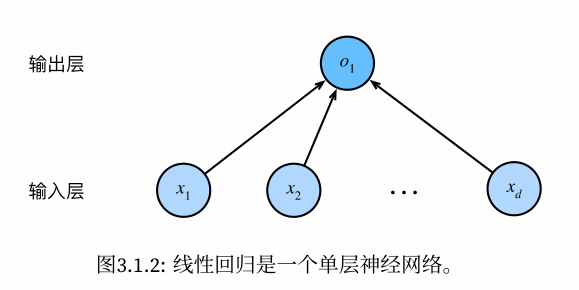
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
#模拟生成含有n个特征的线性回归数据
def synthetic_data(w, b, num_examples):
X = torch.normal(0, 1, (num_examples, len(w)))
y = torch.matmul(X, w) + b
y += torch.normal(0, 0.01, y.shape)
return X, y.reshape((-1, 1))
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices)
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(
indices[i:min(i+batch_size, num_examples)])
yield features[batch_indices], labels[batch_indices]
# true_w = torch.tensor([2.5, -6.2])
# true_b = 1.2
# features, labels = synthetic_data(true_w, true_b, 10)
# next(iter(data_iter(2, features, labels)))
# # (tensor([[-0.0439, -0.0902],
# # [ 1.2628, 1.4977]]),
# # tensor([[ 1.6495],
# # [-4.9359]]))
|