1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
from sklearn.ensemble import GradientBoostingRegressor
model_gbm = GradientBoostingRegressor()
param_grid = [
{'loss' : ['squared_error', 'absolute_error', 'huber', 'quantile'], #与分类任务有变化
'learning_rate' : [0.001, 0.01, 0.1],
'n_estimators' : [100, 200, 300, 500],
'subsample' : [0.5, 0.7, 1]
}
]
grid_search = GridSearchCV(model_gbm, param_grid, cv=5,
scoring="neg_root_mean_squared_error", n_jobs=10)
grid_search.fit(train_X, train_y)
print(grid_search.best_params_)
print(grid_search.best_score_)
gbm_grid_search = grid_search
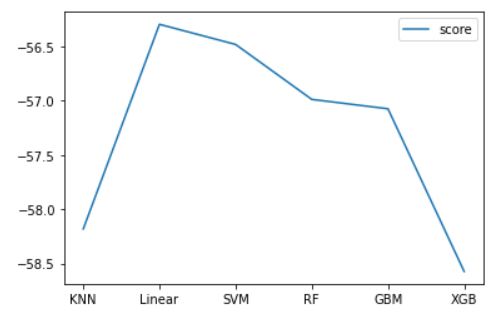
# {'learning_rate': 0.01, 'loss': 'absolute_error', 'n_estimators': 500, 'subsample': 0.5}
# -57.07526918837941
|