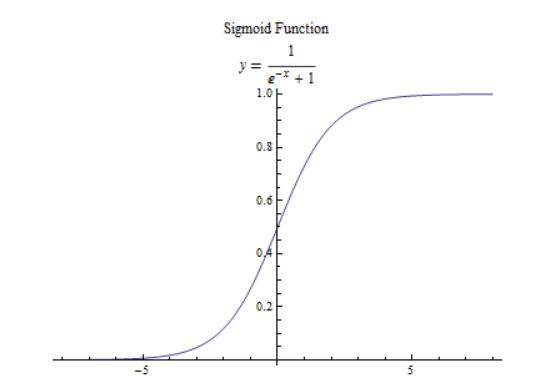
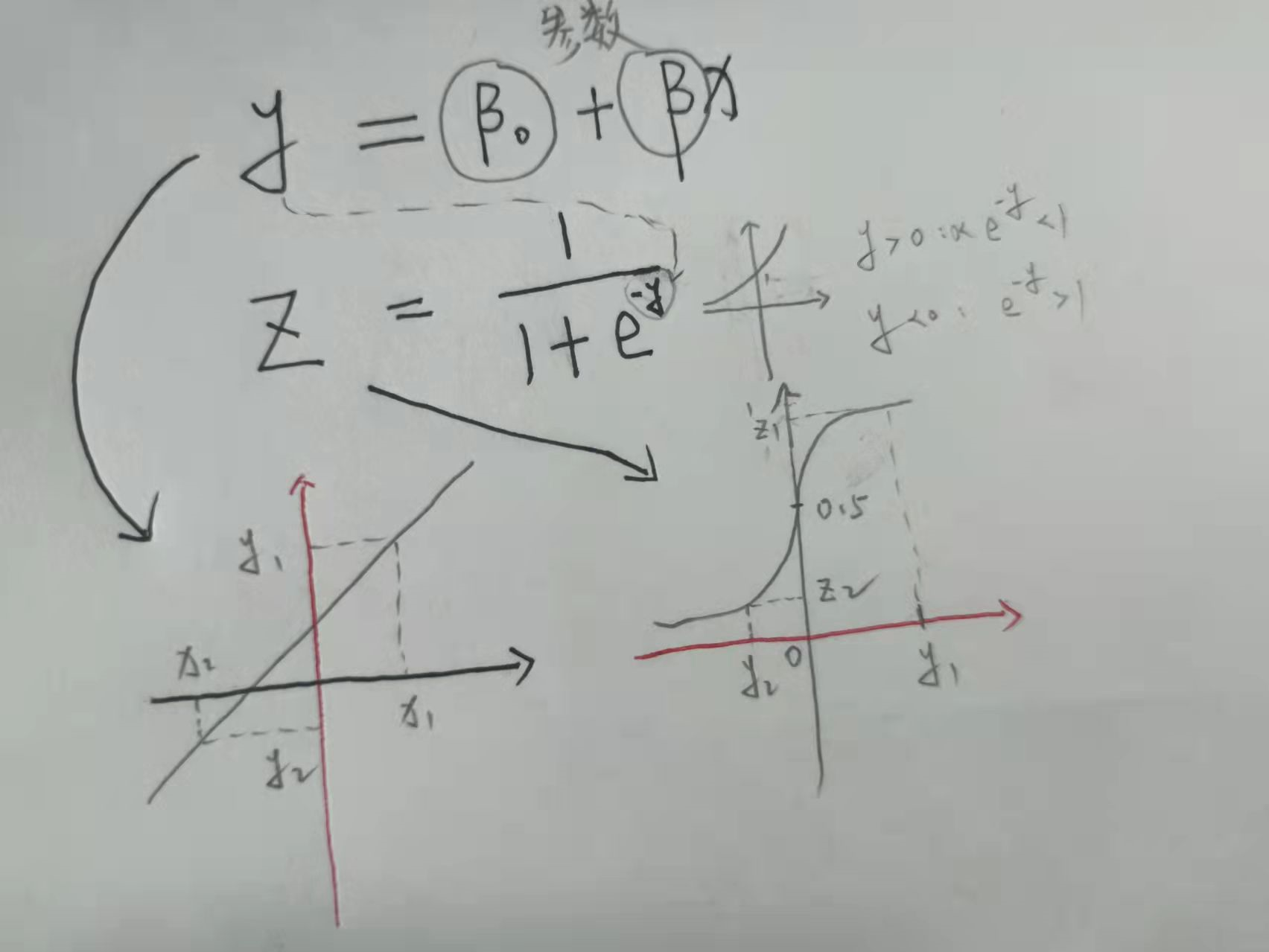
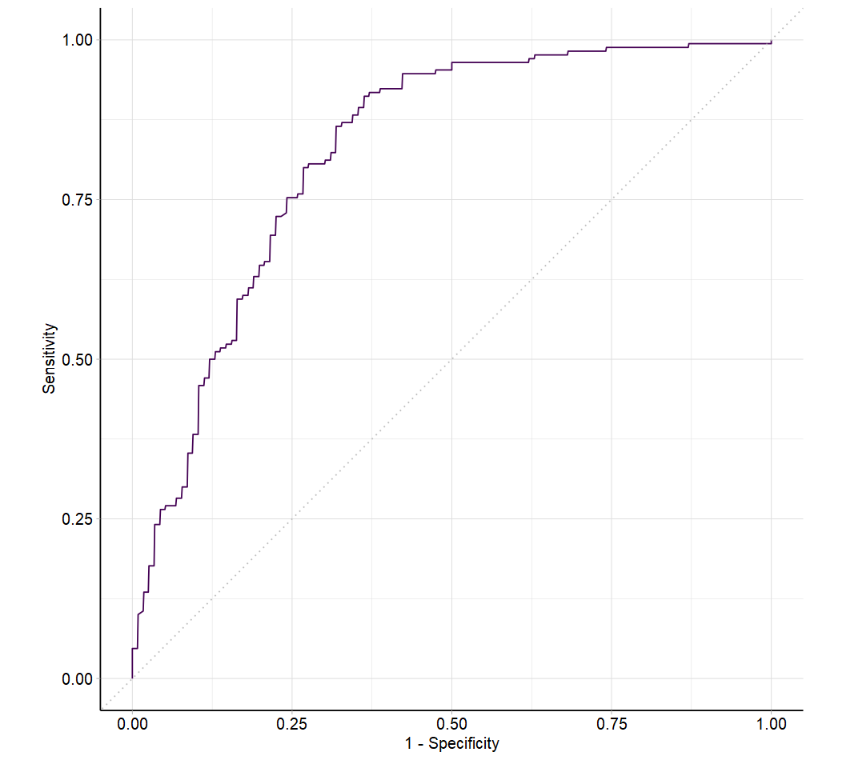
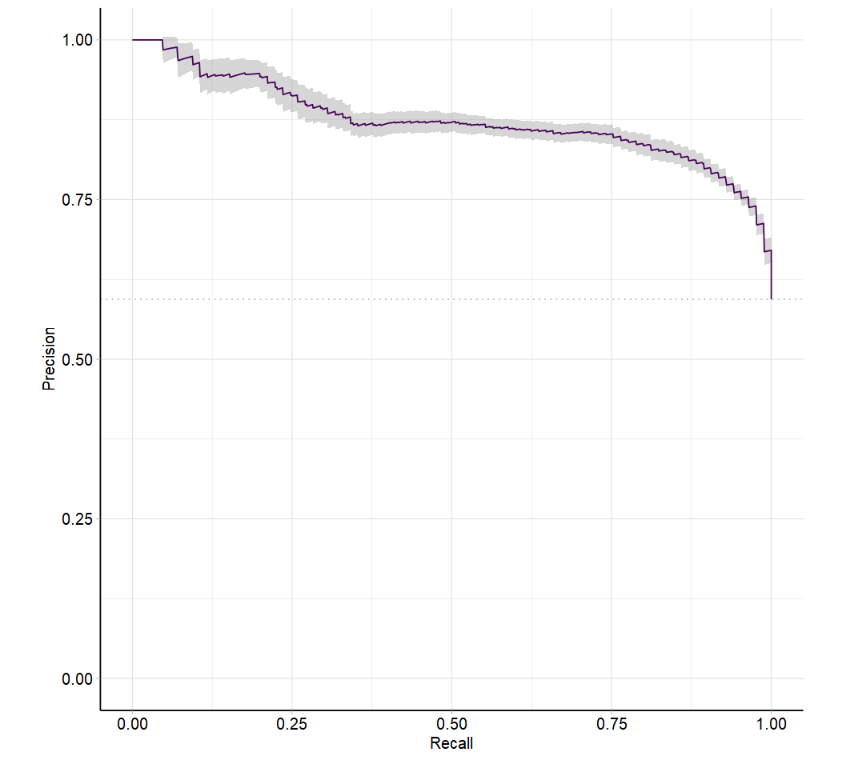
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
data(titanic_train, package = "titanic")
titanicSub = titanic_train[,c("Survived","Sex","Pclass",
"Age","Fare","SibSp","Parch")]
summary(titanicSub)
# Survived Sex Pclass Age Fare SibSp Parch
# Min. :0.0000 Length:891 Min. :1.000 Min. : 0.42 Min. : 0.00 Min. :0.000 Min. :0.0000
# 1st Qu.:0.0000 Class :character 1st Qu.:2.000 1st Qu.:20.12 1st Qu.: 7.91 1st Qu.:0.000 1st Qu.:0.0000
# Median :0.0000 Mode :character Median :3.000 Median :28.00 Median : 14.45 Median :0.000 Median :0.0000
# Mean :0.3838 Mean :2.309 Mean :29.70 Mean : 32.20 Mean :0.523 Mean :0.3816
# 3rd Qu.:1.0000 3rd Qu.:3.000 3rd Qu.:38.00 3rd Qu.: 31.00 3rd Qu.:1.000 3rd Qu.:0.0000
# Max. :1.0000 Max. :3.000 Max. :80.00 Max. :512.33 Max. :8.000 Max. :6.0000
# 第一列:生存与否0/1
# 第二列:性别
# 第三列:头等舱、二等舱、三等舱 1/2/3
# 第四列:年龄
# 第五列:票价
# 第六列:兄弟姐妹+配偶人数
# 第七列:父母和孩子总人数
|