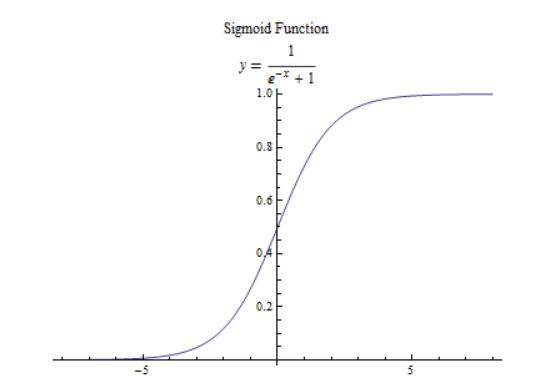
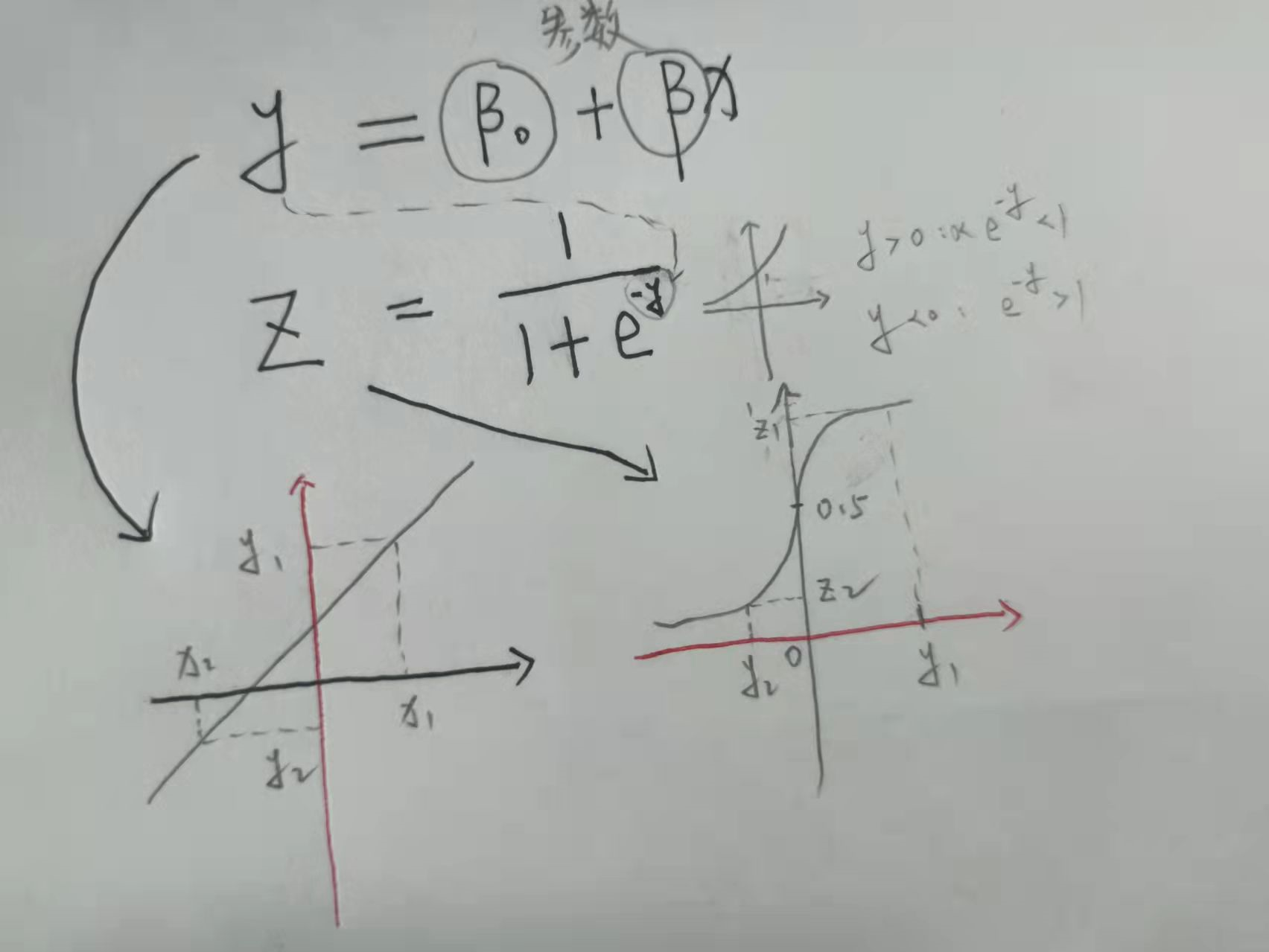
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
#(1)分类变量因子化
#(2)挑选合适特征(第六列+第七列,表示家庭成员数)
fctrs <- c("Survived", "Sex", "Pclass")
titanicClean <- titanicSub %>%
mutate_at(.vars = fctrs, .funs = factor) %>%
mutate(FamSize = SibSp + Parch) %>%
select(Survived, Pclass, Sex, Age, Fare, FamSize)
head(titanicClean)
# Survived Pclass Sex Age Fare FamSize
# 1 0 3 male 22 7.2500 1
# 2 1 1 female 38 71.2833 1
# 3 1 3 female 26 7.9250 0
# 4 1 1 female 35 53.1000 1
# 5 0 3 male 35 8.0500 0
# 6 0 3 male NA 8.4583 0
# (3) 在年龄列有缺失值(NA),需要处理
##如下均值用缺失值代替
imp <- impute(titanicClean, cols = list(Age = imputeMean()))
sum(is.na(imp$data$Age)) #0
|