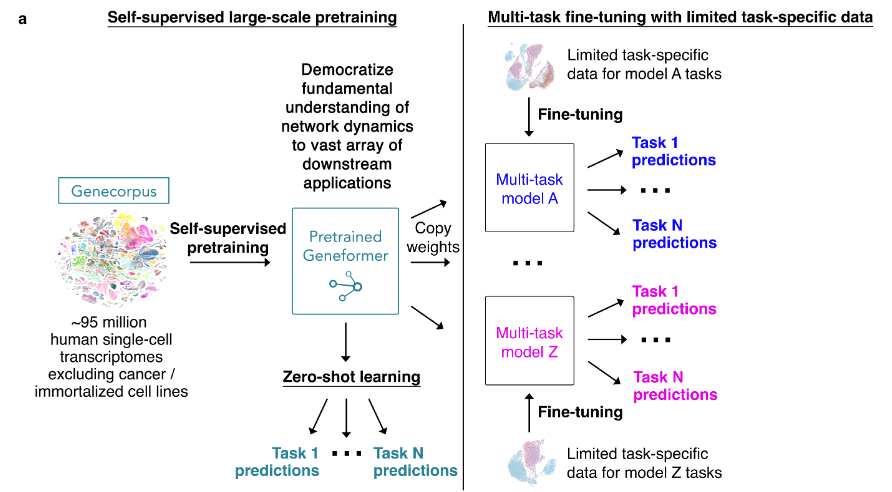
- Quantized multi-task learning for context-specific representations of gene network dynamics
- 2024.8.19, bioRxiv 【预印本】
- https://doi.org/10.1101/2024.08.16.608180
通讯作者:Christina Theodoris (2021 Geneformer的一作,现在应该是独立的PI了)
https://gladstone.org/people/christina-theodoris

背景知识
算法角度
- Multi-task learning 多任务学习
- 设置多个任务,每个任务会计算一个独立的损失函数,总损失函数则是所有任务损失的加权和。
- 训练过程中,共享预训练模型参数,微调模型参数各不相同。
- multi-task learning enables context-specific disease modeling that can yield contextual predictions of candidate therapeutic targets for human disease.
- Continual learning 持续学习
- 机器学习模型在不断接收新任务或新数据时,能够持续学习和更新其知识。分为三类:Class/Task/Domain incremental continual learning
- 挑战:catastrophic forgetting
- https://neptune.ai/blog/continual-learning-methods-and-application
性能角度- QLoRA: Quantization | Low-Rank Adapters
- Model Quantization 模型量化 :4-bit字节压缩预训练模型
- Low-Rank Adapters 低秩适配器
- 微调部分的参数层通过LoRA低秩矩阵分解降低需要更新参数量
- 微调/推理过程 Resource-efficient
1. 第一次预训练
-
数据量:~103M human scRNA-seq
- 经质控筛选(e.g. 去除肿瘤细胞)后,保留95M
- 词汇表:20275 (1) 20271 protein coding genes; (2) 4 special tokens (PAD, MASK, CLS, EOS )
-
模型框架(gf-12L-95M-i4096)
- 最大序列长度:4096,此外在有效序列的前后增加了CLS与EOS
- 注意力层:12 | Embedding size: 512 | Heads: 8
- Masked ratio: 15% | 最大学习率:5e-4 (warmup steps 5000) | Batch: 1 (梯度累计:4)
- 44 hours, 8 H100 GPUs
- 还有4个版本:GF-6L-30M-I2048, GF-12L-30M-I2048, GF-12L-95M-I2048, GF-20L95M-I4096
-
Zero-shot性能:基于上述预训练模型获得cell/gene的zero-shot Embedding(不更新模型参数),相比Geneformer v1在多个微调任务中表现具有优势。
- 值得一提的是:这里的cell embedding是来自倒数第二层的CLS Embedding,后面的MTL以及ISP,都是来自最后一层的CLS Embedding
- 在Geneformer V1版本中, Cell Embedding是所有基因Embedding的均值。
- 微调性能结果是基于25次超参数寻参得到的(例如不同的学习率等)
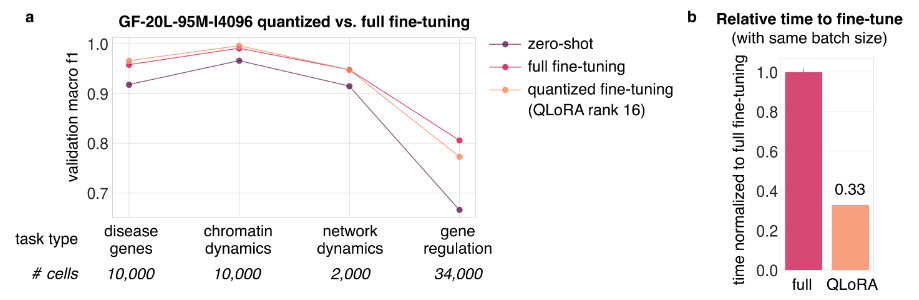
- 模型量化:使用量化模型(e.g. 4-bit, rank16)可以使得微调任务性能影响不大的情况下,显著降低了成本(时间,内存)。
- full fine-tuning:超参数包括被冻结的层数,top 0/7/14 layers
- quantized fine-tuning:同上
- zero-shot (指上面的结果)
2. 多任务微调学习
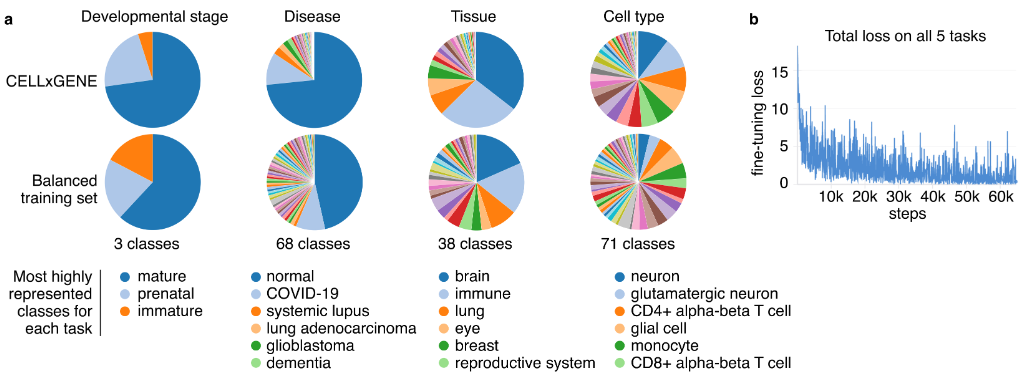
- 背景:疾病的发生过程可能与多个角度相关(例如cell type, tissue, developmental stage..)。基于单任务学习(例如Geneformer v1基于细胞类型)得到的cell/gene表示,缺少全面性,尤其是应用在ISP
- 数据量:~43M annotated cells from CELLxGENE,
- 71 cell types,38 tissues,68 diseases, 3 developmental stages
- MTL设计:5个细胞分类微调任务的损失之和作为总损失更新模型
- cell types/tissue/disease types/disease vs normal/developmental stage
- 在每个任务的类别存在不平衡时,采用多种采样策略【详见method】
- 最终发现在5个任务中均表现良好,此时得到的cell Embedding更具有代表性(用于后续的ISP)
- 基于微调后的MTL模型,采用量化技术得到的cell embedding信息没有丢失,同时推理成本较低。
- 在ISP方面,量化模型的基因模拟敲除所发生的shift趋势相同,同样成本降低
3. 第二次预训练及对应微调
- Domain-specific continual learning:肿瘤单细胞特征
- 数据量: ~14M cells from cancer studies
- 包括1%的第一阶段训练数据,以避免 “catastrophic forgetting”
- 训练方式与第一阶段相同,采用15% masked gene的自监督学习。其中包括三种学习率的设置方式。
- 如下图b,左侧绿线表示第一次预训练的学习率变;而右侧三条线便是3种学习率设置方案的continual learning
- 结合图c,发现其中最优的一种方案(是与第一次的预训练最大学习率相同)
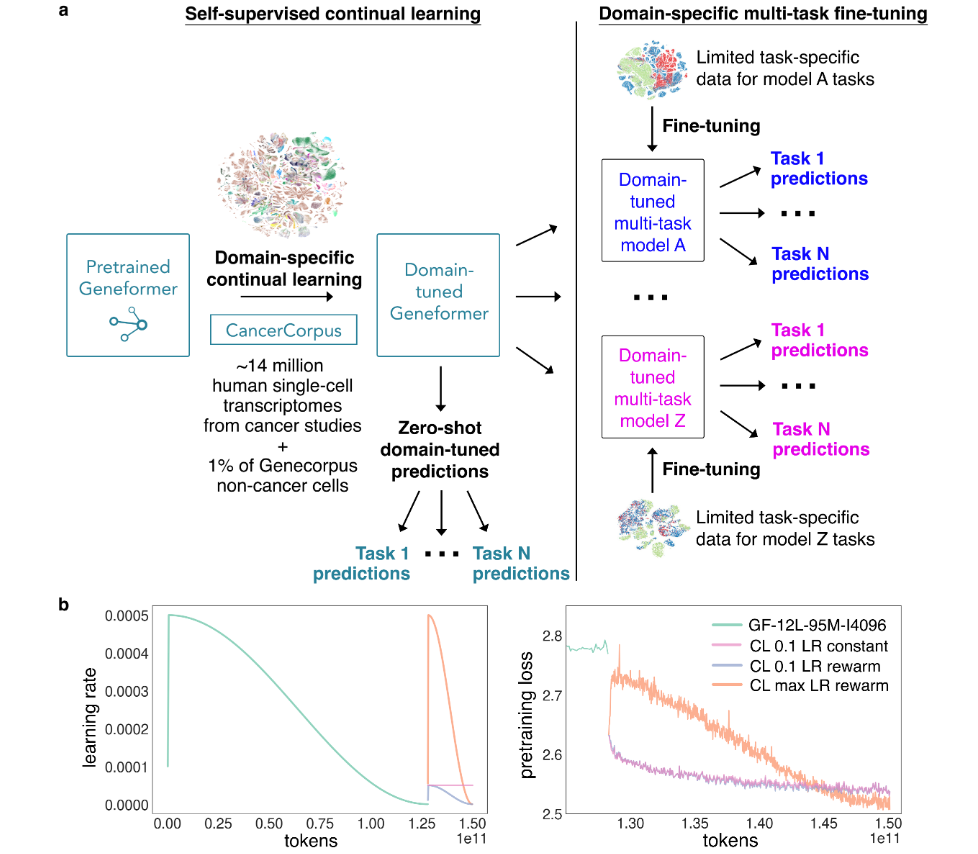
- 接下来继续对上述预训练模型,设计一个MTL细胞分类微调任务:
- 在结直肠癌单细胞数据下的3个任务:MMR status/cell type/cell subtype
- 发现在cell subtype存在上皮细胞的亚型注释时,二次预训练模型表现更好
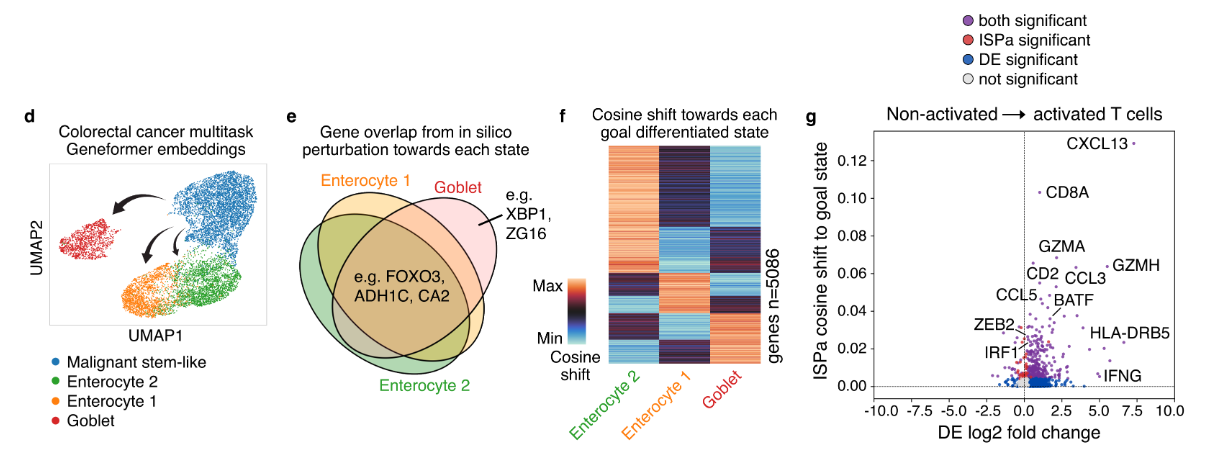
4. 基于TME的ISP实验
基于上述的微调模型,进行了两次结直肠癌相关的ISP实验
TASK-1:
- In silico overexpression
- from epithelial cancer cells to normal epithelial (下图的e-f)
TASK-2:
- In silico overexpression
- from quiescent T cell to activated T cell state
- 与已报道的CRISPR结果相一致