题目:In silico prediction of potential drug-induced nephrotoxicity with machine learning methods
期刊 | 日期 : Journal of Applied Toxicology | 11 April 2022
简介:标准的机器学习模型分析流程,从数据收集到数据整理,从训练模型到评价模型。
1、数据收集
1.1 标签数据
(1)从SIDER、DrugBank、ChEMBL以及TCM@taiwan等4个数据库收集了1366个标签化合物
(2)使用PubChem获得每个化合物的PubCID与canonical SMILE;
(3)使用Pipeline Pilot(https://www.accelrys.com) 筛选无效的化合物
- 无机和有机金属化合物
- 将salt forms转为parent form
- 去重
(4)经上一部筛选保留777个化合物
- 125 天然化合物
- 652 化药化合物
(5)基于文献与最新更新数据,收集70个外部数据集
- 基于文献:29个天然化合物、11个化药化合物
- 2021FDA最新批准药物:11个。
1.2 特征数据
使用Padel Descriptor software(https://github.com/ecrl/padelpy)软件,计算每个化合物的9种分子指纹。
- Atom Pair 2D fingerprint (AP2DFP, 780 bits)
- Estate fingerprint (EstateFP, 79 bits)
- CDK extended fingerprint (ExtFP, 1024 bits)
- CDK fingerprint (FP, 1024 bits)
- CDK graph only fingerprint (GraphFP, 1024 bits)
- Klekota–Roth fingerprint (KRFP, 4860 bits)
- MACCS fingerprint (MACCSFP, 166 bits)
- PubChem fingerprint (PubChemFP, 881 bits)
- substructure fingerprint (SubFP, 307 bits)
2 训练模型
2.1 机器学习算法
(1)使用scikit-learn包提供的8种算法建立机器学习分类模型。
(2)结合上面的8种指纹特征,共建立得到72个机器学习模型。
- Artificial neural network (ANN)
- LightGBM
- Random forest (RF)
- SVM
- C4.5 decision tree (DT)
- KNN
- naïve Bayes (NB)
- scalable end-to-end tree boosting system (XGBoost)
2.2 数据集划分
(1)将777个标签数据按照9:1比例,划分成训练集(train)与内部验证集(internal validation)
(2)结合上面提及的70个标签化合物(external validation),共有3份数据集。
(3)检验所有化合物之间特征分布无不平衡情况
- 比较3类数据集的Molecular/AlogP特征分布(左);
- 计算化合物两两相似性Tanimoto similarity coefficient(右)
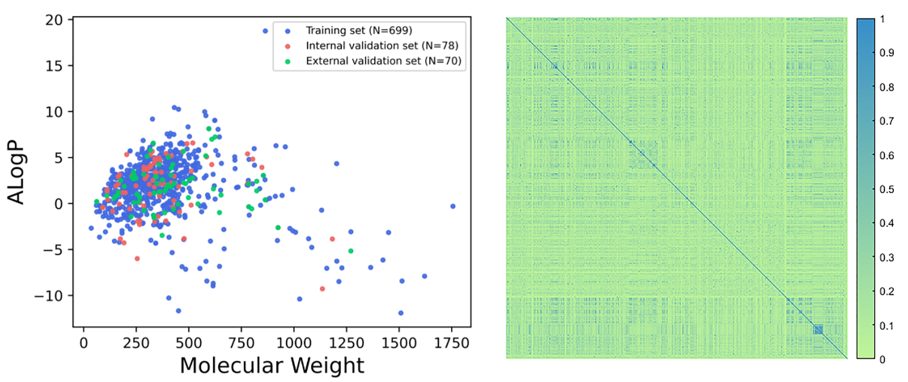
2.3 模型训练
(1)在训练集中,使用10次的10折交叉验证方式优化参数(grid search)
(2)使用下述多个指标对模型预测结果进行评价
- AUC :overall predictive performance
- ACC :prediction of the overall sample data.
- SE(sensitivity):positive sample data
- SP(specificity):negative sample data.
- F1:harmonic mean of recall and precision.
- MCC(for external validation)
4、模型评价
(1)对于每个优化好的模型(72个)在internal validation set中作第一次验证,优选综合评价最好的6个模型。
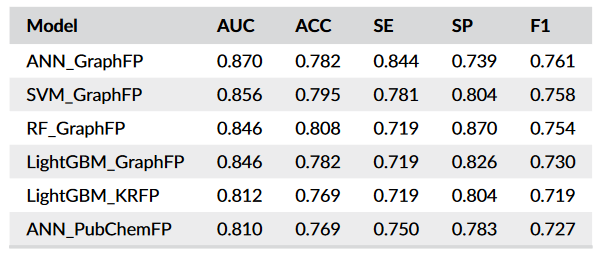
(2)使用这6个模型在external validation set中作第二次验证,分3个角度进行(单独天然药、单独化药、混合数据)。

5、衍生
-
模型的适用域applicability domain (AD)
-
分析警示结构 structural alerts(SARpy工具)