Network Pharmacology-Based Analysis on the Potential Biological Mechanisms of Sinisan Against Non-Alcoholic Fatty Liver Disease(四逆散–非酒精性脂肪肝)
27 August 2021
Front Pharmacol, IF=5.8

- 分析思路
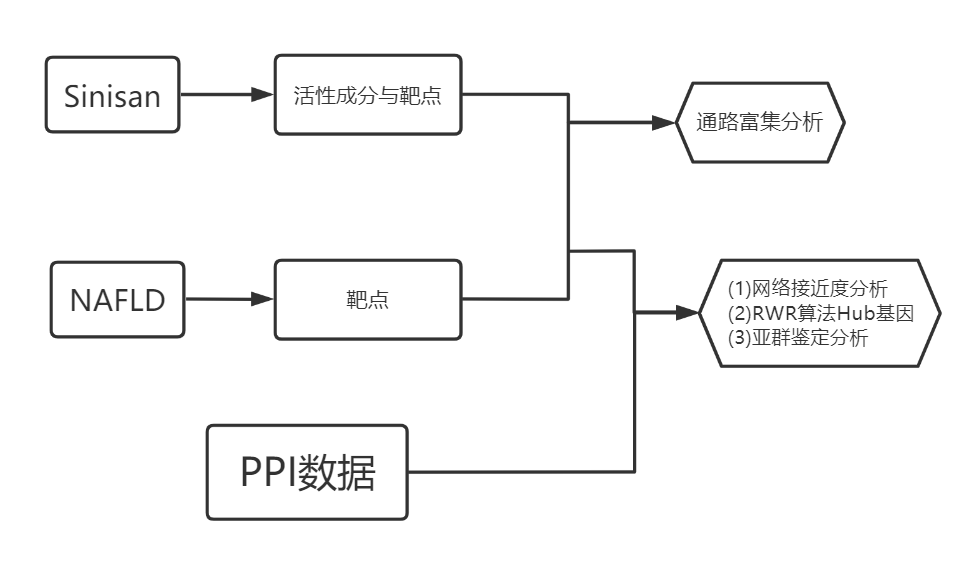
- 文章的流程图
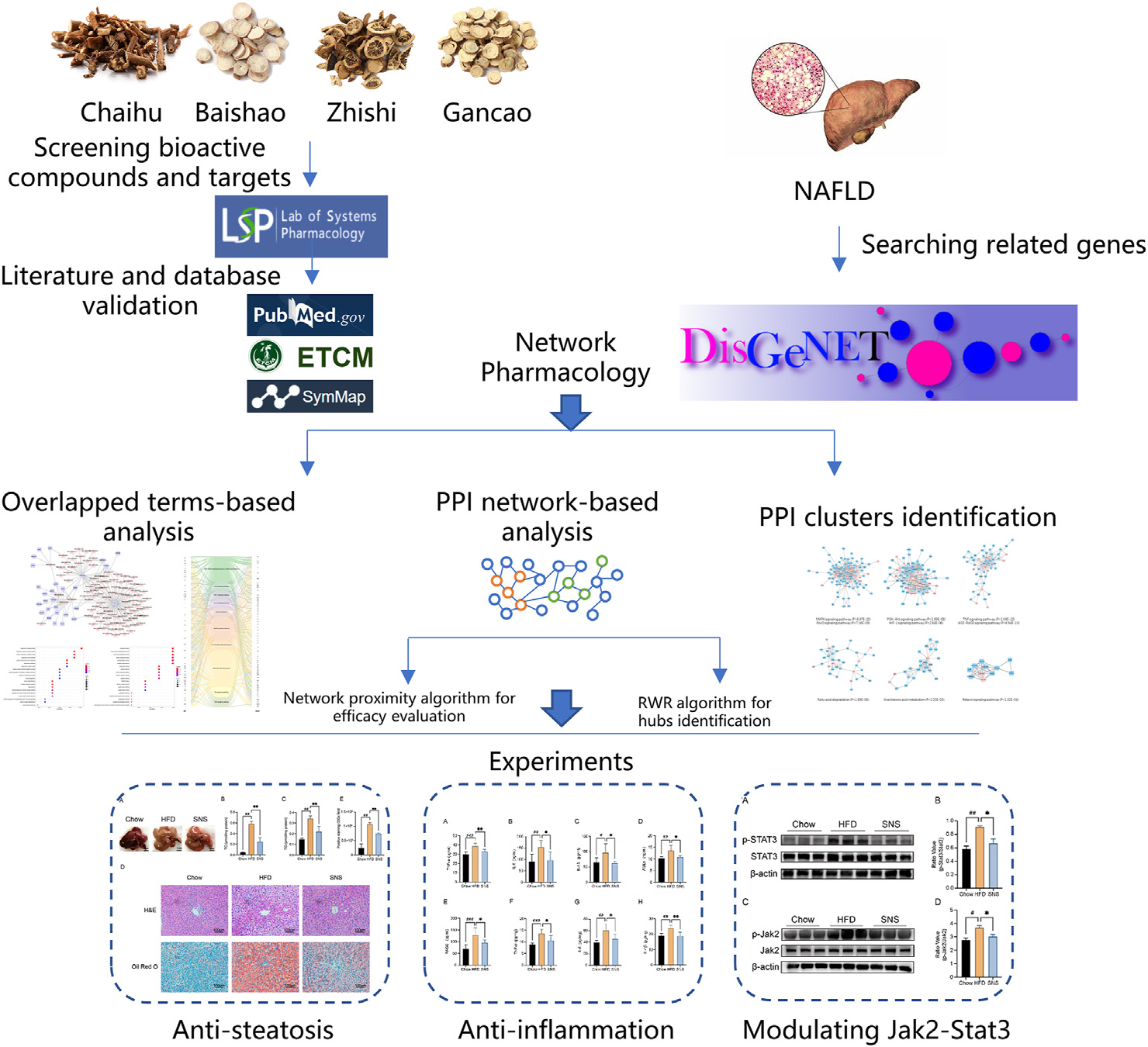
1、数据收集
1.1 TCM数据
-
四味中药:柴胡、白芍、枳实、甘草
-
TCMSP数据库,筛选条件:OB ≥ 30% ; DL ≥ 0.18。
OB: systemic bioavailability after oral absorption and distribution;
DL: structural similarity between compounds and clinically used drugs in the DrugBank database
1.2 疾病数据
- DisGeNET 数据库
- 搜索关键词:“Non-alcoholic Fatty Liver Disease”, “Nonalcoholic Steatohepatitis”, and “Fibrosis, Liver”
- 过滤掉 BEFREE text mining genes 结果
- 得到306个NAFLD基因
1.3 PPI数据
文章基于两个数据库建立了两个PPI网络
- (1)dataset constructed by Professor Barabasi’s team
- 15 commonly used databases with experimental evidence and the inhouse confirmed data without inferred information.
- https://ccsb.dana-farber.org/interactome-data.html
- http://www.interactome-atlas.org/download
- 共得到16677个蛋白的243603条互作关系,简记为Bnet
- (2)STRING
- Homo sapiens; confidence score ≥0.9
- 共得到9941个蛋白的227186条互作关系,简记为Snet
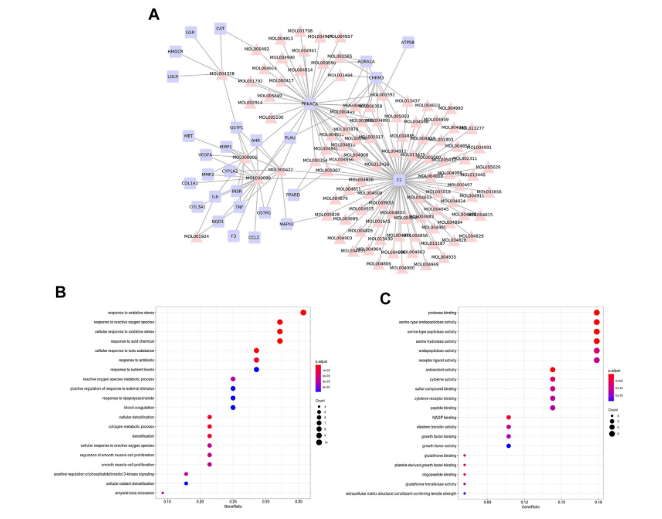
2、通路富集分析
-
ClusterProfiler包
-
TCM与Disease各自的靶点分别进行GO(BP/CC/MF)、KEGG富集分析,比较是否富集到相同的通路。
-
TCM与Disease的交集靶点富集到哪些通路。
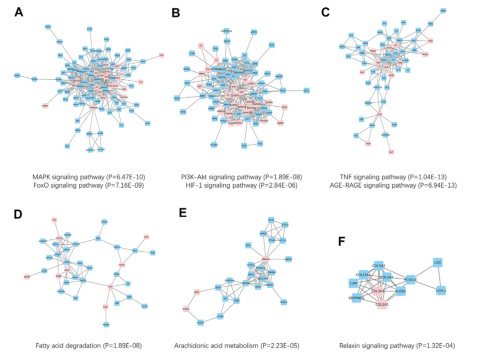
3、网络分析
3.1 网络接近度计算
- 如下公式,计算在Bnet中TCM靶点群与Disease靶点群的距离。其中
V表示Disease靶点群,T表示TCM靶点群;计算对于TCM靶点群的所有靶点能到Disease靶点群(的任一靶点)的最短距离的均值。
$$ d_c(V,T) = \frac{1}{||T||}\sum_{t\in T}min_{v\in V}d(v,t) $$
- 为了衡量TCM靶点群到Disease靶点群的距离相对远近,进行Z值标准化。
- 具体做法是大量模拟任意与TCM靶点群相同数量的蛋白群,同上公式计算其与Disease靶点群的距离;计算均值与方差,再按下公式计算出Z值。
$$ Z_{d_{c}} = \frac{d_c-\mu_{d_{c}(V,T)}}{\sigma_{d_{c}(V,T)}} $$
- 结果 d=1.05,Z=-9.51,显著低于随机分布;表明TCM靶点群到Disease靶点群距离近,具有显著意义
3.2 RWR算法计算hub基因
- 从全部的PPI数据(Bnet),提取出仅包含TCM与Disease靶点的 sub-PPI,sub-Bnet。根据PPI关系,计算出Disease靶点群中的哪些靶点最容易收到TCM靶点群的影响。
- 算法为RWR重启随机游走算法。使用RandomWalkRestartMH包计算,将TCM靶点群视为种子节点,重启概率设为0.75。笔记链接–
$$ p_{t+1}^T = (1-r)Mp_t^T + rP_{0}^T $$
- 得到最易受到影响的Top10节点:STAT3, CTNNB1, MAPK1, MAPK3, AGT, NQO1, TOP2A, FDFT1, ALDH4A1, and KCNH2
3.3 亚群鉴定分析
-
从全部的PPI数据(Snet),提取出仅包含TCM与Disease靶点的 sub-PPI,sub-Snet;包含1425条互作关系
-
使用Cytoscape软件的 ClusterMaker 2插件鉴定6个包含TCM与Disease靶点的subcluster;并通过KEGG富集找到每个subcluster最相关的通路。