1、html基础与xpath语法
1.1 html基础
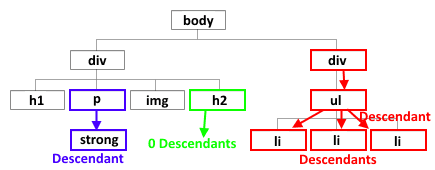
- 大多数网页内容都是html结构组织的,在我理解就是有众多节点(node)组成的树状结构;
- 而我们想要爬取的内容就是其中的某个或者某些节点的文本标签或者属性中。
- 更多可参考: (1)https://www.w3cschool.cn/html/html-basic.html (2)HTML零基础入门教程(详细)_ZONGXP的博客-CSDN博客_html5零基础入门教程
1.2 xpath语法
- 一个html网页往往包含非常多的节点,如何准确、快速定位到目标节点是爬虫过程中的关键问题;而xpath语法可以帮助我们实现这一点;
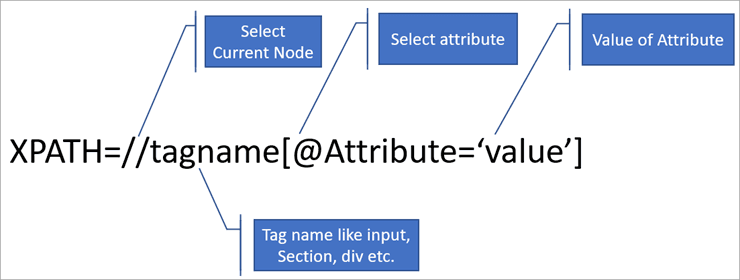
- xpath简单来说是帮助我们解析html结构的一种语言,简单入门比较推荐B站的视频:【智源学院】20分钟带你搞懂XPath — Scrapy数据解析神器_哔哩哔哩_bilibili
- 语法应用笔记推荐: (1)XPath定位语法总结_Q0717168的博客-CSDN博客_xpath定位语法 (2)https://learnku.com/articles/50459
2、xpath工具推荐
2.1 浏览器自带的定位功能
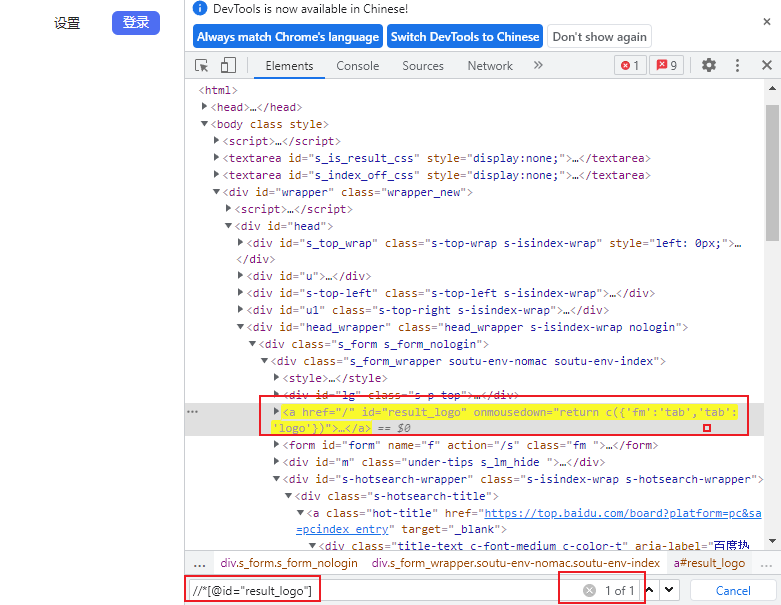
- 打开目标网页→ 右键单击“检查”→点击审查元素窗口左上角箭头→网页界面选择感兴趣内容→选中元素窗口高亮部分→右键单击,选择copy xpath
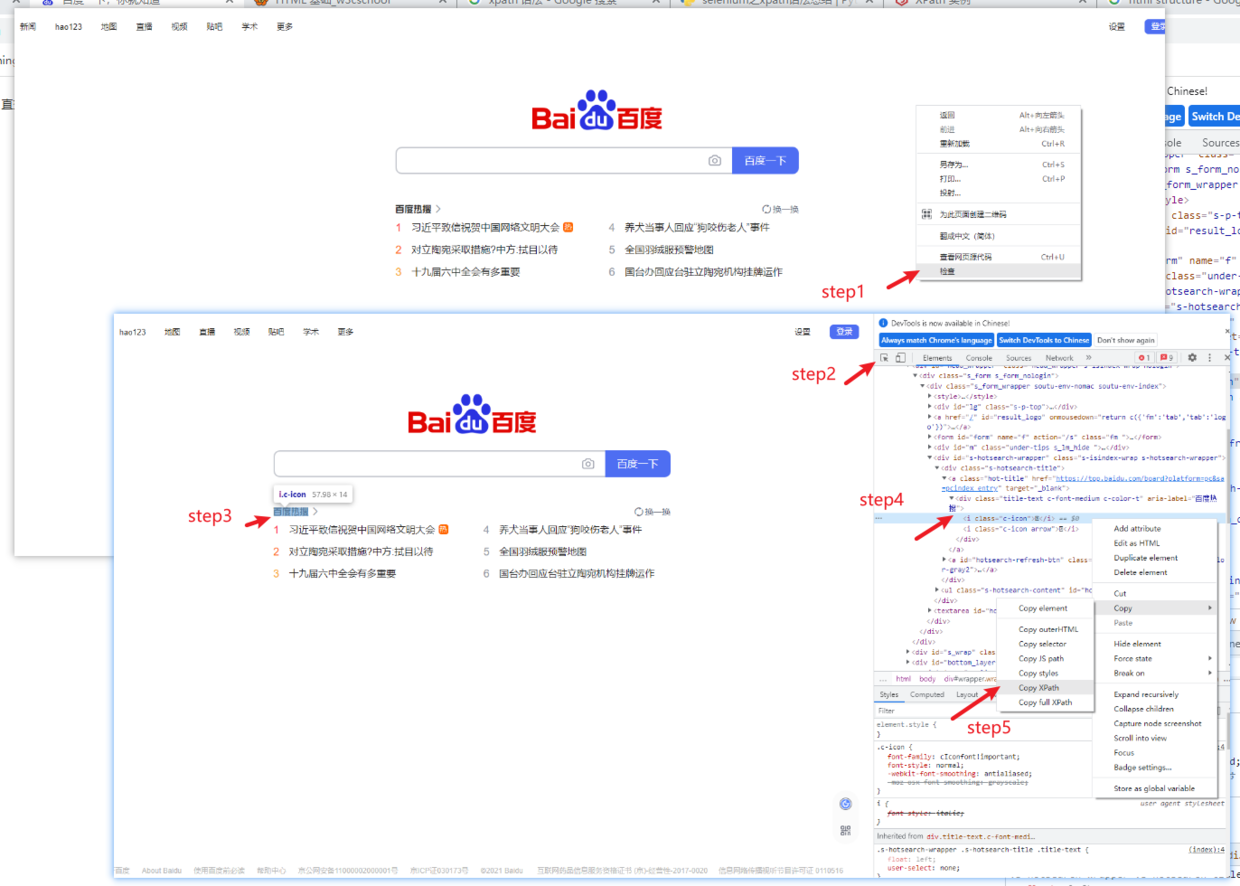
- 在元素窗口,使用ctrl+F快捷键,可以不断调试xpath
2.2 google插件之XPath Helper
- 可以用来非常方便地调试、验证我们的xpath
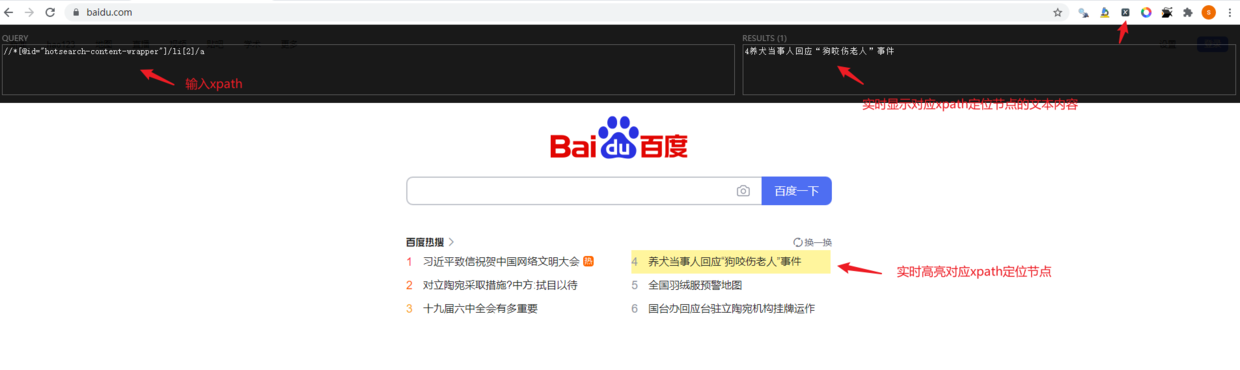
2.3 google插件之SelectorGadget
- 该插件只需要我们在网页选择好感兴趣的标签,然后会自动生成能够定位到目标节点的xpath路径;
- 不过有一个缺点就是:SelectorGadget生成的xpath路径一般比较复杂,如果我们自己花心思调试一下(2.1)往往会生成简洁的xpath路径【通往罗马的道路不止一条】
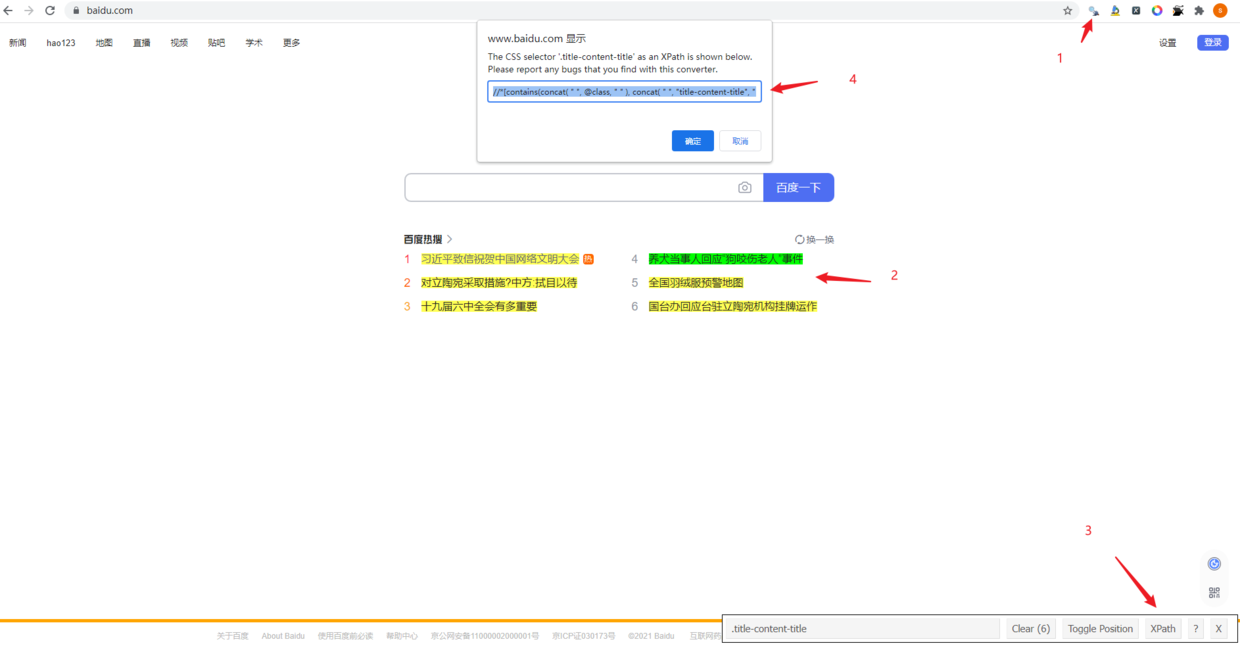
3、R语言爬虫流程
一开始学习R语言爬虫时,直接
xml2::read_html()对提交的网址进行解析,但经常会出现提交正确的xpath路径,但是没有提取到节点内容的尴尬结果{xml_nodeset (0)}。 后来了解到针对动态网页的selenium爬取方法,尝试了一下果然可以得到预期的结果。而且我觉得动静态网页通吃,因此以后的R语言爬虫都采用下述的流程来操作。
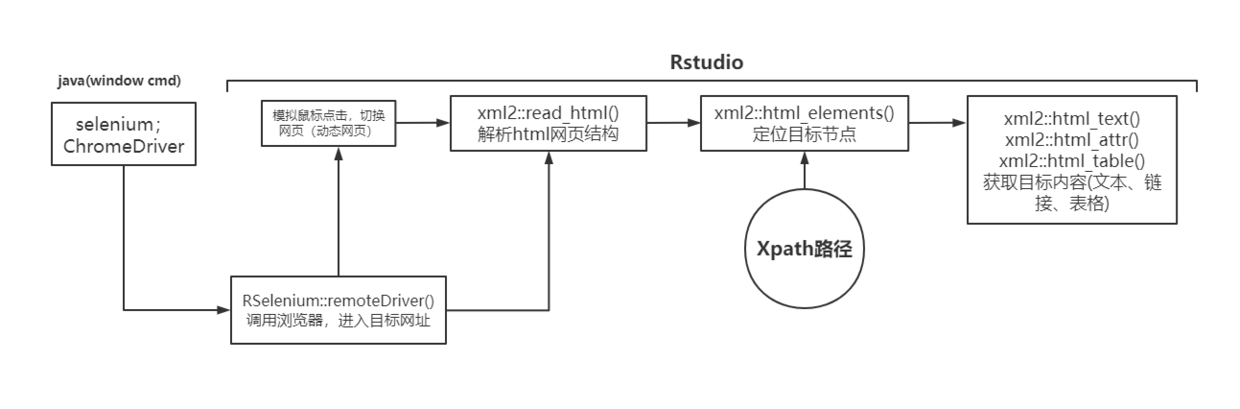
- 参考笔记 :微信公众号:老俊俊的生信笔记–R语言爬虫系列笔记 R 爬虫之爬取文献信息 (qq.com)
4、selenium相关配置(window) ⭐
参考笔记:https://zhuanlan.zhihu.com/p/24772389
step1:安装Java
- 下载、安装容易,但是将java命令添加到环境变量需要仔细一点 网上有很多笔记,例如:Java JDK安装和配置 - Java教程™ (yiibai.com)
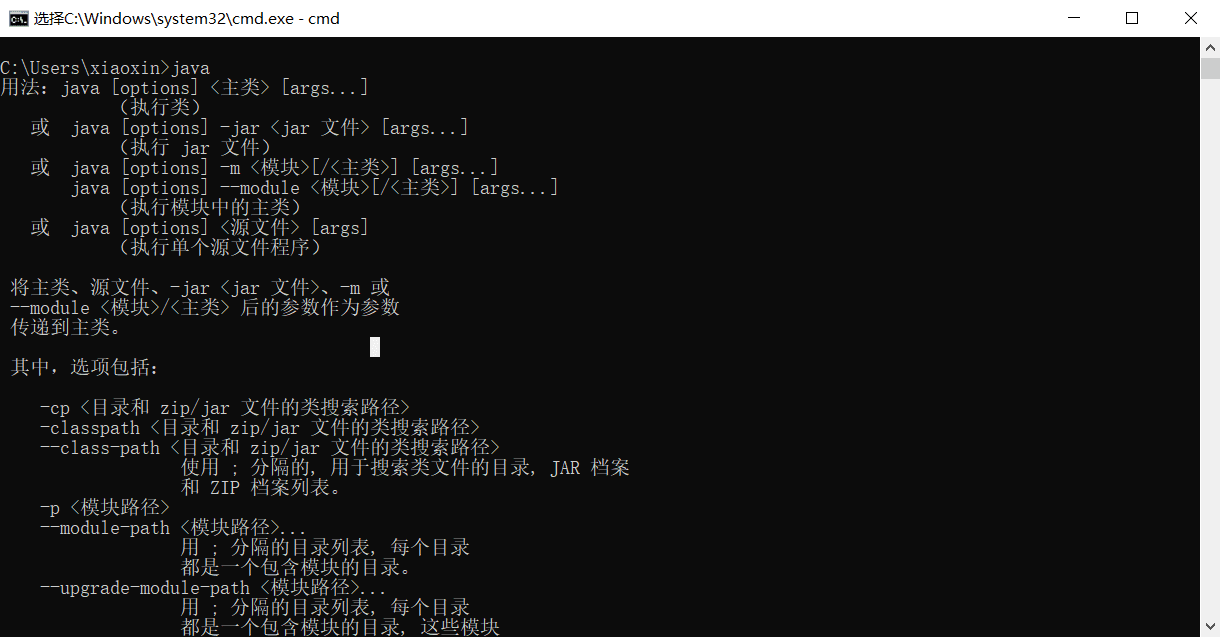
- 如果在window的cmd平台调用
java命令,出现如下结果,说明安装、配置java成功了
step2:chrome浏览器相关
- 首先要下载、安装Chrome浏览器,根据提示选择默认安装路径即可 https://www.google.cn/chrome/
- 然后要下载ChromeDriver.exe https://sites.google.com/chromium.org/driver/
有两点要注意(1)下载ChromeDriver版本要与Chrome版本一致(我的是94系列);(2)储存路径要与
chrome.exe在一个文件夹内;我的安装路径是 C:\Program Files\Google\Chrome\Application
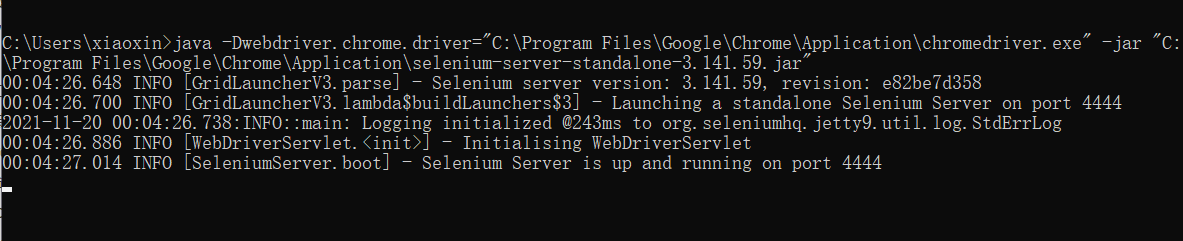
step3:下载selenium-server-standalone.jar
- 下载地址:http://selenium-release.storage.googleapis.com/index.html 有很多版本可供选择,我下载的是3.14版本;同时为了管理方便,与上面文件放在了同一文件夹内;
最后如果调用下面命令,出现如下图的结果说明selenium相关环境都配置好了
|
|
5、豆瓣爬虫实战
前期准备
(1)准备selenium环境
- 打开window命令行界面:win + r ,输入
cmd回车;然后输入以下命令。待成功出现上图结果后,最小化界面即可。之后的操作都基于R
|
|

(2)安装、加载R包
|
|
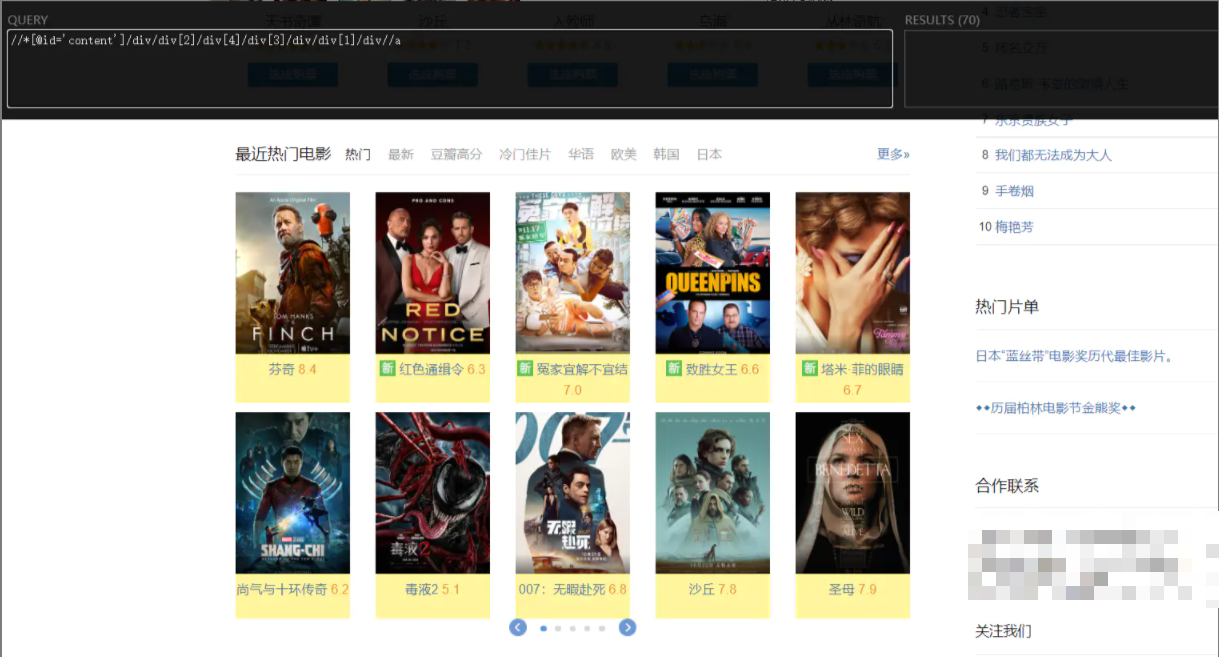
实战1:爬取最近热门电影的名字、评分
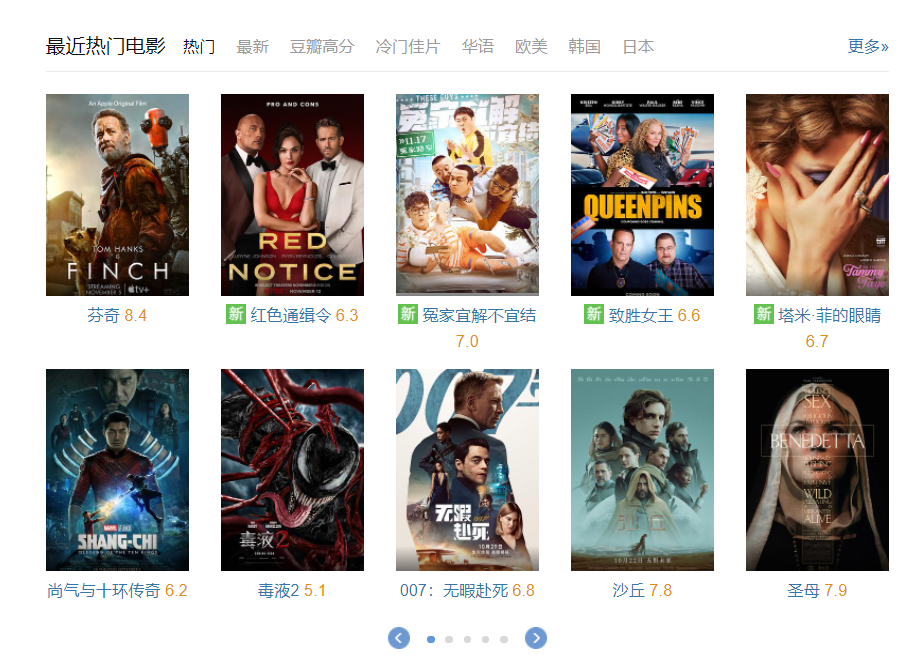
- 网址链接:https://movie.douban.com/
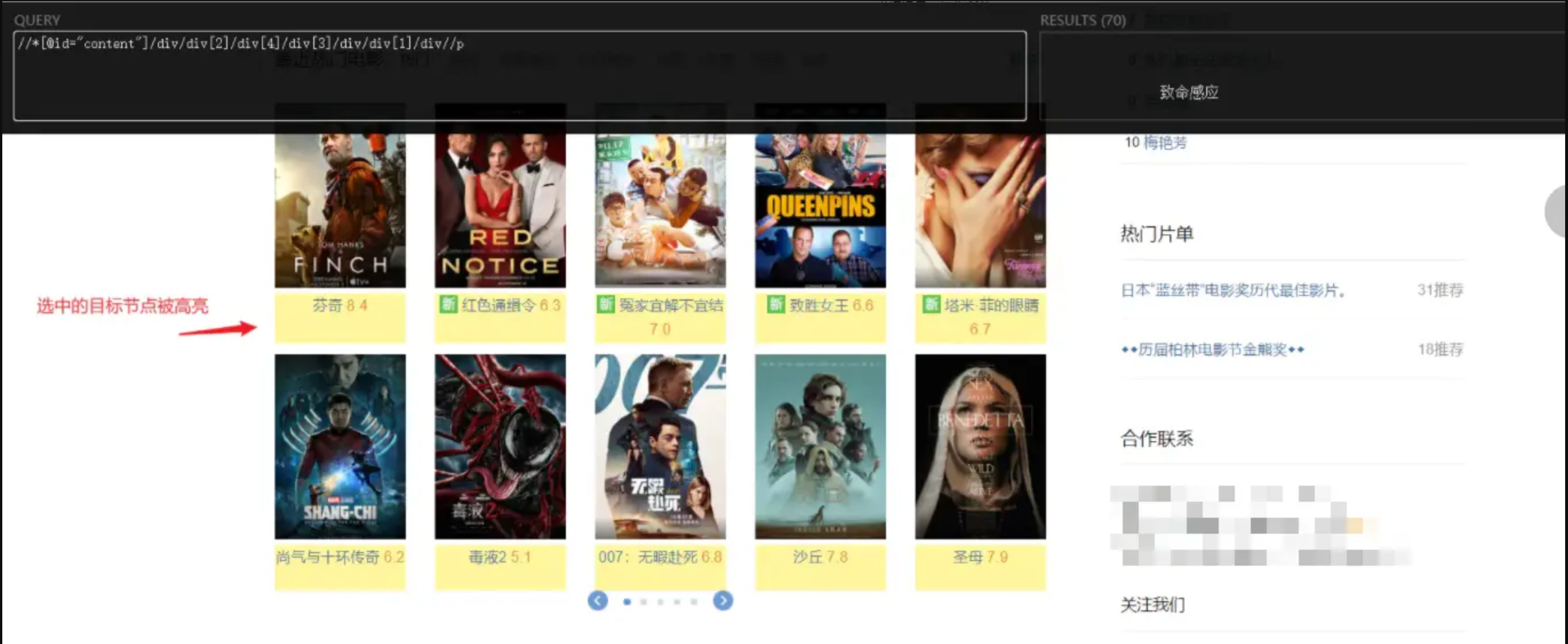
- 目标i节点的xpath路径:
//*[@id="content"]/div/div[2]/div[4]/div[3]/div/div[1]/div//p
Step1:调用浏览器,进入目标网址
|
|
Step2:获得、解析当前网页html内容
|
|
Step3:应用xpath路径,定位、获取目标节点内容
html_text()可获得目标节点的文本内容
|
|
关于目标节点的xpath路径确认是很关键的一。其次当xpath路径本身含有双引号时,创建字符串时两边要改到单引号。
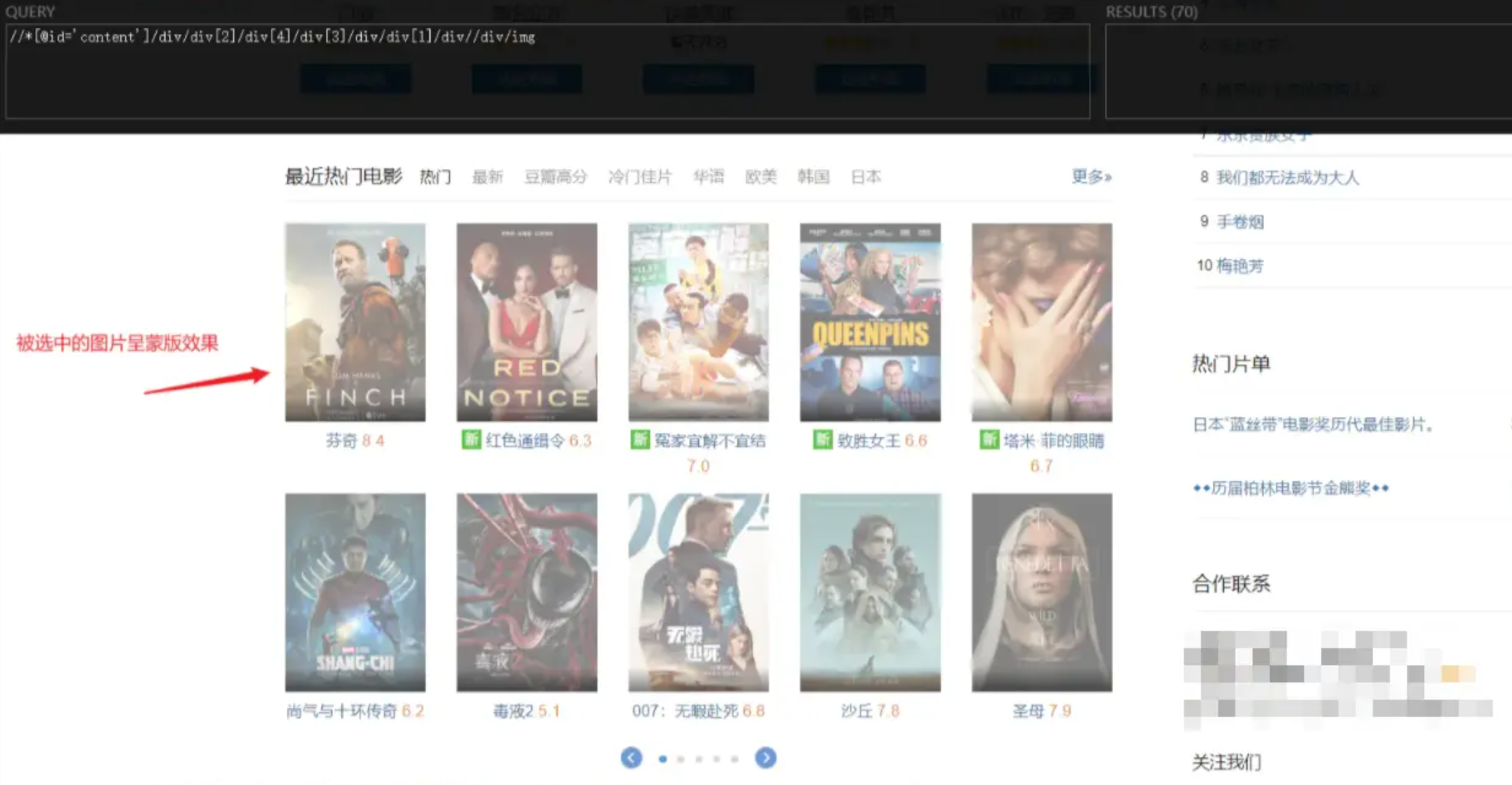
实战2:爬取最近热门电影的图片、详情页链接
- 爬取图片时本质上还是获得图片对应的链接,然后再下载即可。
- 而链接内容一般作为节点的属性值,而不会在网页显示出来。
html_attr()可获得目标节点的属性值- 图片节点xapth:
//*[@id='content']/div/div[2]/div[4]/div[3]/div/div[1]/div//div/img
(1)爬取图片
|
|
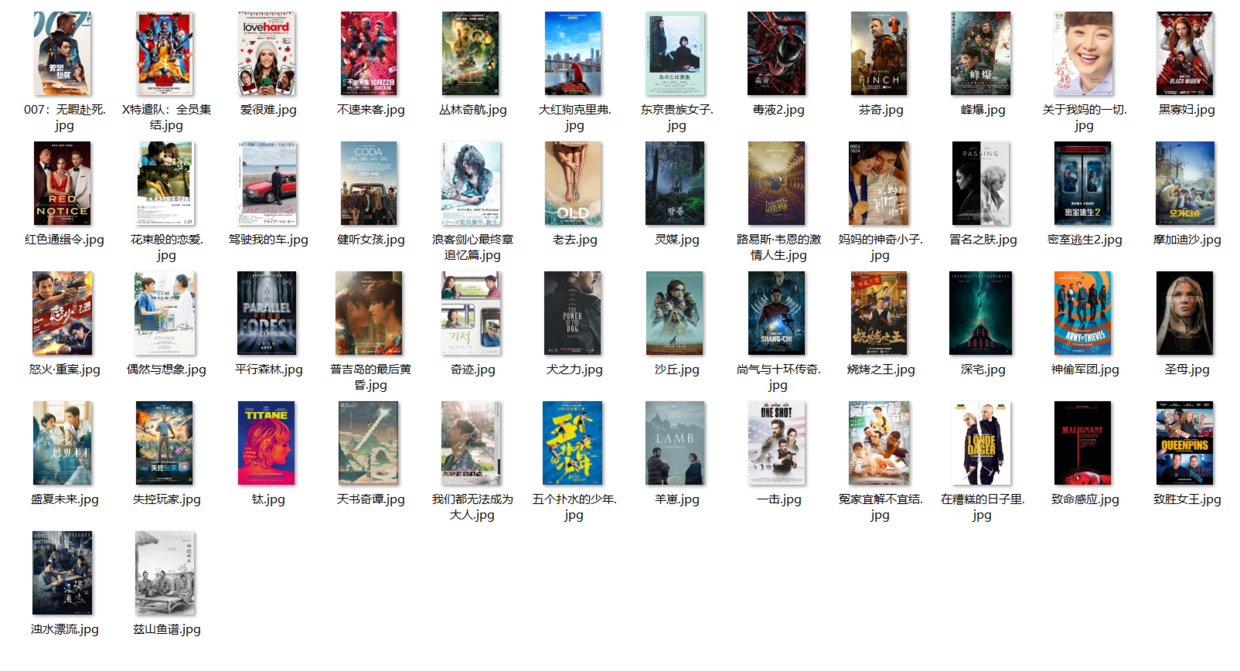
- 由于可以通过点击电影名进入电影详情页,由此判定在电影名节点的属性包含链接属性
- 电影名节点xapth:
//*[@id='content']/div/div[2]/div[4]/div[3]/div/div[1]/div//a
(2)爬取链接
|
|
实战3:爬取不同类型标签的电影名、评分(模拟鼠标点击翻页)
- Selenium的强大之处至于可以模拟鼠标操作进行网页选择、切换;
- 如下图,我们想获得框选出的8种类别的电影名与评分
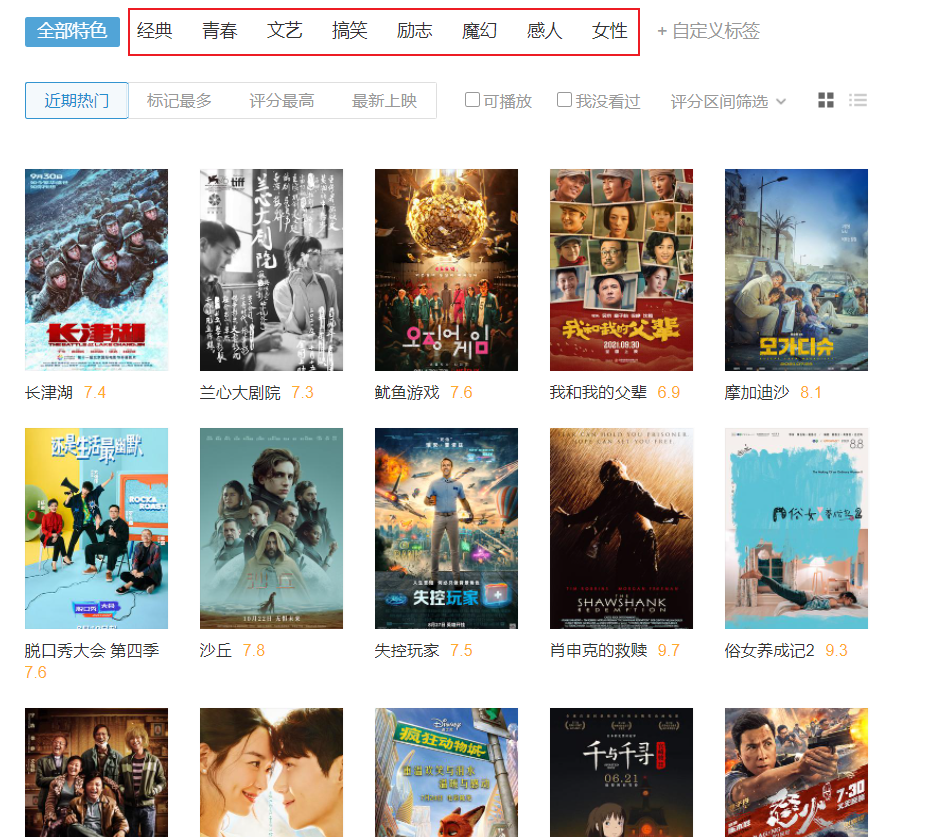 - 目标网址:`https://movie.douban.com/tag/#/`
### Step1:调用浏览器,进入目标网址
```R
remDr <- remoteDriver(remoteServerAddr = "localhost",
port = 4444, browserName = "chrome")
remDr$open() # 打开浏览器
remDr$navigate("https://movie.douban.com") #进入网址
```
### Step2:获得、解析当前网页html内容
```R
webpage <- read_html(remDr$getPageSource()[[1]][1]) #获得网页的html内容
```
### Step3:我们需要模拟鼠标点击那个节点、点多少次
```R
movie_type = webpage %>% html_elements(xpath = "//*[@id='app']/div/div[1]/div[1]/ul[5]//span") %>%
html_text() %>% .[2:9]
movie_type
# [1] "经典" "青春" "文艺" "搞笑" "励志" "魔幻" "感人" "女性"
```
### Step4:循环点击、进行目标文本爬取
```R
movie_stat = list()
for(i in seq(movie_type)){
# i=1
print(i)
#鼠标点击节点的xpath路径
button_xpath = sprintf("//*[@id='app']/div/div[1]/div[1]/ul[5]//span[contains(text(), '%s')]",
movie_type[i])
#该节点的鼠标点击属性
button = remDr$findElement(using ='xpath', value = button_xpath)
#模拟鼠标点击该节点
button$clickElement()
Sys.sleep(3)
#更新当前html内容
webpage <- read_html(remDr$getPageSource()[[1]][1])
xpath_name = "//*[@id='app']/div/div[1]/div[3]//span"
#结合目标文本的xpath路径爬取内容
test_raw = html_elements(webpage, xpath = xpath_name) %>% html_text()
movie_stat[[i]] = data.frame(Type = movie_type[i],
Name=test_raw[seq(2,60,3)],
Score=test_raw[seq(3,60,3)])
}
movie_stats = do.call(rbind, movie_stat)
- 目标网址:`https://movie.douban.com/tag/#/`
### Step1:调用浏览器,进入目标网址
```R
remDr <- remoteDriver(remoteServerAddr = "localhost",
port = 4444, browserName = "chrome")
remDr$open() # 打开浏览器
remDr$navigate("https://movie.douban.com") #进入网址
```
### Step2:获得、解析当前网页html内容
```R
webpage <- read_html(remDr$getPageSource()[[1]][1]) #获得网页的html内容
```
### Step3:我们需要模拟鼠标点击那个节点、点多少次
```R
movie_type = webpage %>% html_elements(xpath = "//*[@id='app']/div/div[1]/div[1]/ul[5]//span") %>%
html_text() %>% .[2:9]
movie_type
# [1] "经典" "青春" "文艺" "搞笑" "励志" "魔幻" "感人" "女性"
```
### Step4:循环点击、进行目标文本爬取
```R
movie_stat = list()
for(i in seq(movie_type)){
# i=1
print(i)
#鼠标点击节点的xpath路径
button_xpath = sprintf("//*[@id='app']/div/div[1]/div[1]/ul[5]//span[contains(text(), '%s')]",
movie_type[i])
#该节点的鼠标点击属性
button = remDr$findElement(using ='xpath', value = button_xpath)
#模拟鼠标点击该节点
button$clickElement()
Sys.sleep(3)
#更新当前html内容
webpage <- read_html(remDr$getPageSource()[[1]][1])
xpath_name = "//*[@id='app']/div/div[1]/div[3]//span"
#结合目标文本的xpath路径爬取内容
test_raw = html_elements(webpage, xpath = xpath_name) %>% html_text()
movie_stat[[i]] = data.frame(Type = movie_type[i],
Name=test_raw[seq(2,60,3)],
Score=test_raw[seq(3,60,3)])
}
movie_stats = do.call(rbind, movie_stat)
head(movie_stats)
Type Name Score
1 经典 沙丘 7.8
2 经典 肖申克的救赎 9.7
3 经典 我不是药神 9.0
4 经典 疯狂动物城 9.2
5 经典 千与千寻 9.4
6 经典 泰坦尼克号 9.4
table(movie_stats$Type)
感人 搞笑 经典 励志 魔幻 女性 青春 文艺
20 20 20 20 20 20 20 20
|
|