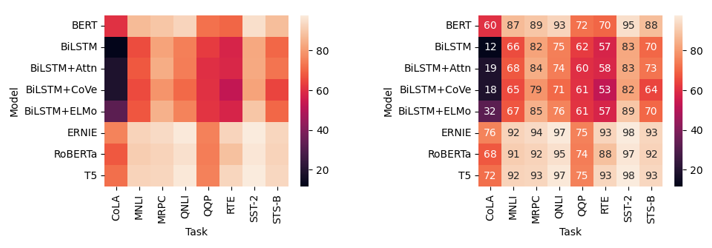
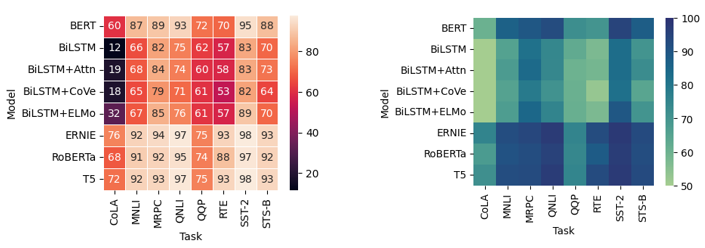
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
iris = sns.load_dataset("iris")
species = iris.pop("species")
print(iris.head())
# sepal_length sepal_width petal_length petal_width
# 0 5.1 3.5 1.4 0.2
# 1 4.9 3.0 1.4 0.2
# 2 4.7 3.2 1.3 0.2
# 3 4.6 3.1 1.5 0.2
# 4 5.0 3.6 1.4 0.2
# 1) 自动新建自己的图
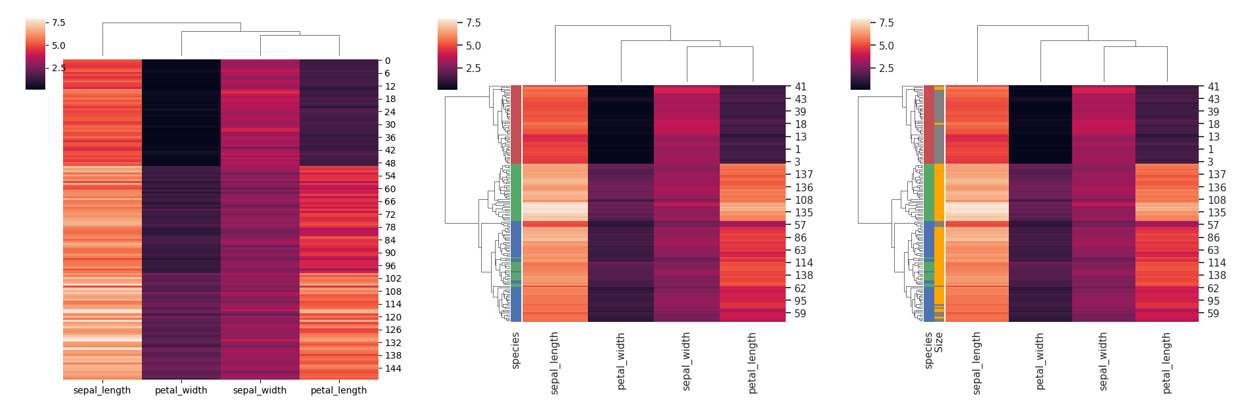
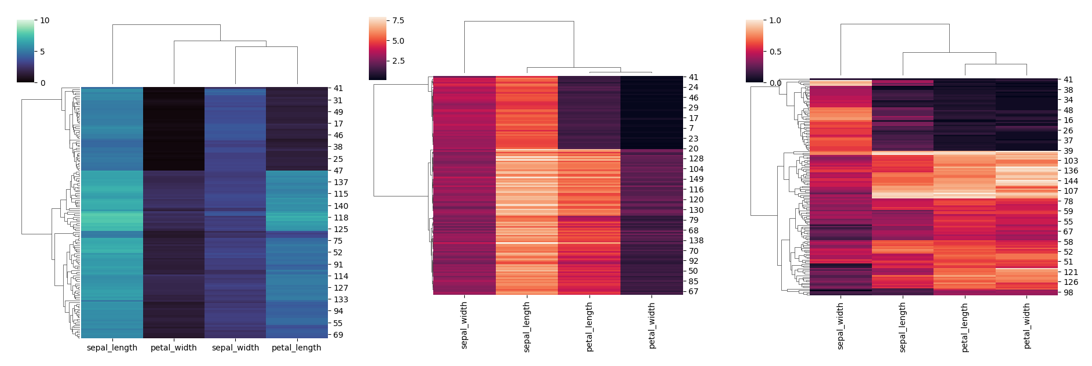
sns.clustermap(
iris,
figsize=(6, 6),
row_cluster=False, # 是否行聚类
dendrogram_ratio=(.1, .1), # 分别设置行列聚类图高度,若设置为0即不显示
)
# 2) 增加一列注释meta
lut = dict(zip(species.unique(), "rbg"))
row_colors = species.map(lut) # pandas.core.series.Series
row_colors.head() # index对应热图的列名, value对应颜色
# 0 r
# 1 r
# 2 r
# 3 r
# 4 r
sns.clustermap(
iris, row_colors=row_colors,
figsize=(6, 6),
)
# 3) 增加两列注释meta
size_category = pd.Series(
np.where(iris["sepal_length"] > 5.5, "large", "small"),
index=iris.index,
name="Size"
).map({"large": "orange", "small": "gray"})
row_colors2 =pd.concat([row_colors, size_category], axis=1)
print(row_colors2.head())
# species Size
# 0 r gray
# 1 r gray
# 2 r gray
# 3 r gray
# 4 r gray
sns.clustermap(
iris, row_colors=row_colors2,
figsize=(6, 6),
)
|